
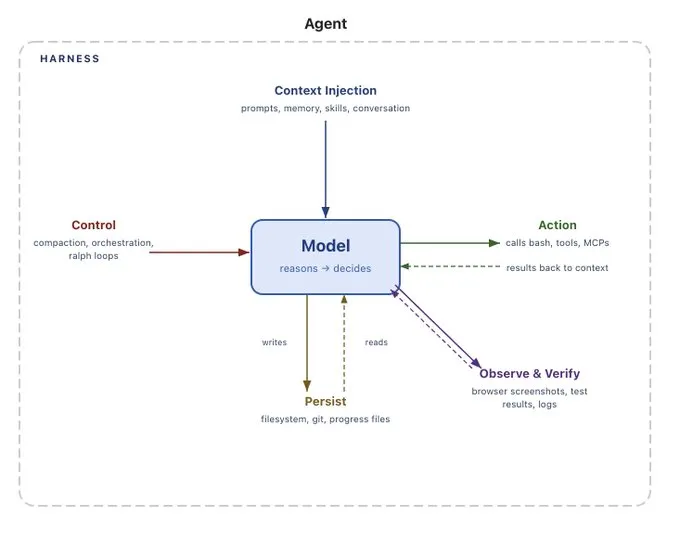
Agent harnesses are becoming the dominant way to build agents, and they are not going anywhere. These harnesses are intimately tied to agent memory. If you used a closed harness - especially if it’s behind a proprietary API - you are choosing to yield control of your agent’s memory to a third party. Memory is incredibly important to creating good and sticky agentic experiences. This creates incredible lock in. Memory - and therefor harnesses - should be open, so that you own your own memory
Agent Harnesses are how you build agents, and they’re not going anywhere
The “best” way to build agentic systems has changed dramatically over the past three years. When ChatGPT came out, all you could do were simple RAG chains (LangChain). Then the models got a little better, and could create more complex flows (LangGraph). Then they got a lot better, and that gave rise to a new type of scaffolding - agent harnesses.
Examples of agent harnesses include Claude Code, Deep Agents, Pi (powers OpenClaw), OpenCode, Codex, Letta Code, and many more.
Agent harnesses are not going away.
There is sometimes sentiment that models will absorb more and more of the scaffolding. This is not true. What has happened (and will continue to happen) is that a lot of the scaffolding needed in 2023 is no longer needed. But this has been replaced by other types of scaffolding. An agent, by definition, is an LLM interacting with tools and other sources of data. There will always be a system around the LLM to facilitate that type of interaction. Need evidence? When Claude Code’s source code was leaked, there was 512k lines of code. That code is the harness. Even the makers of the best model in the world are investing heavily in harnesses.
When things like web search are built into OpenAI and Anthropic’s APIs - they are not “part of the model”. Rather, they are part of a lightweight harness that sits behind their APIs and orchestrates the model with those web search APIs (via nothing other than tool calling).
Harnesses are tied to memory
Sarah Wooders wrote a great blog on why “memory isn’t a plugin (it’s the harness)”, and I couldn’t agree with it more.
There is sometimes sentiment that memory is a standalone service, separate from any particular harness. At this point in time, that is not true.
A large responsibility of the harness is to interact with context. As Sarah puts it:
Asking to plug memory into an agent harness is like asking to plug driving into a car. Managing context, and therefore memory, is a core capability and responsibility of the agent harness.
Memory is just a form of context. Short term memory (messages in the conversation, large tool call results) are handled by the harness. Long term memory (cross session memory) needs to be updated and read by the harness. Sarah lists out many other ways the harness is tied to memory:
How is the AGENTS.md or CLAUDE.md file loaded into context?How is skill metadata shown to the agents? (in the system prompt? in system messages?)Can the agent modify its own system instructions?What survives compaction, and what's lost?Are interactions stored and made queryable?How is memory metadata presented to the agent?How is the current working directory represented? How much filesystem information is exposed?
Right now, memory as a concept is in it’s infancy. It’s so early for memory. Transparently, we see that long term memory is often not part of the MVP. First you need to get an agent working generally, then you can worry about personalization. This means that we (as an industry) are still figuring out memory. This means there are not well known or common abstractions for memory. If memory does become more known, and as we discover best practices, it is possible that separate memory systems start to make sense. But not at this point in time. Right now, as Sarah said, “ultimately, how the harness manages context and state in general is the foundation for agent memory.”
if you don't own your harness, you don't own your memory
The harness is intimately tied to memory.
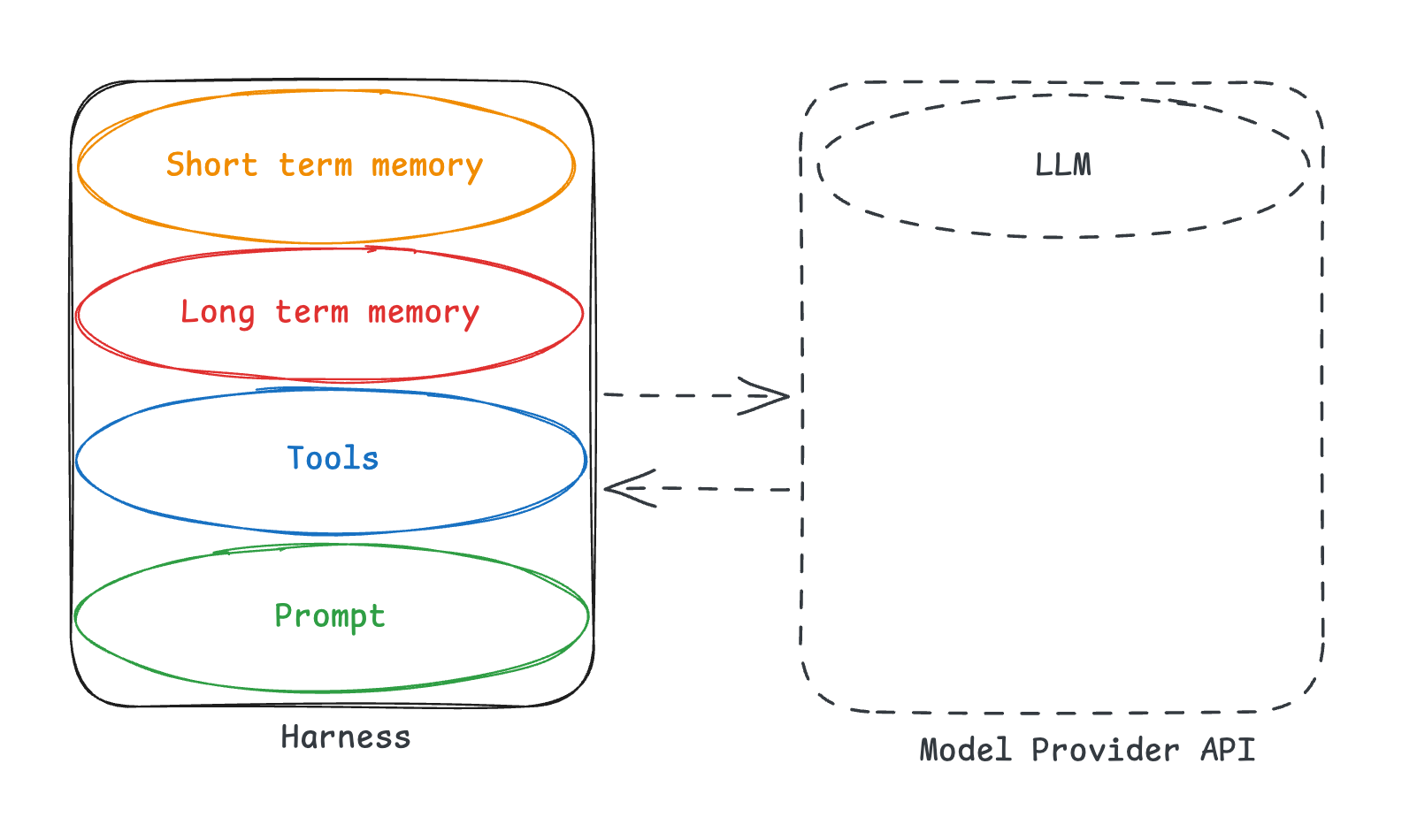
If you use a closed harness, especially if its behind an API, you don’t own your memory.
This manifests itself in several ways.
Mildly bad: If you use a stateful API (like OpenAI’s Responses API, or Anthropic’s server side compaction), you are storing state on their server. If you want to swap models and resume previous threads - that is no longer doable.
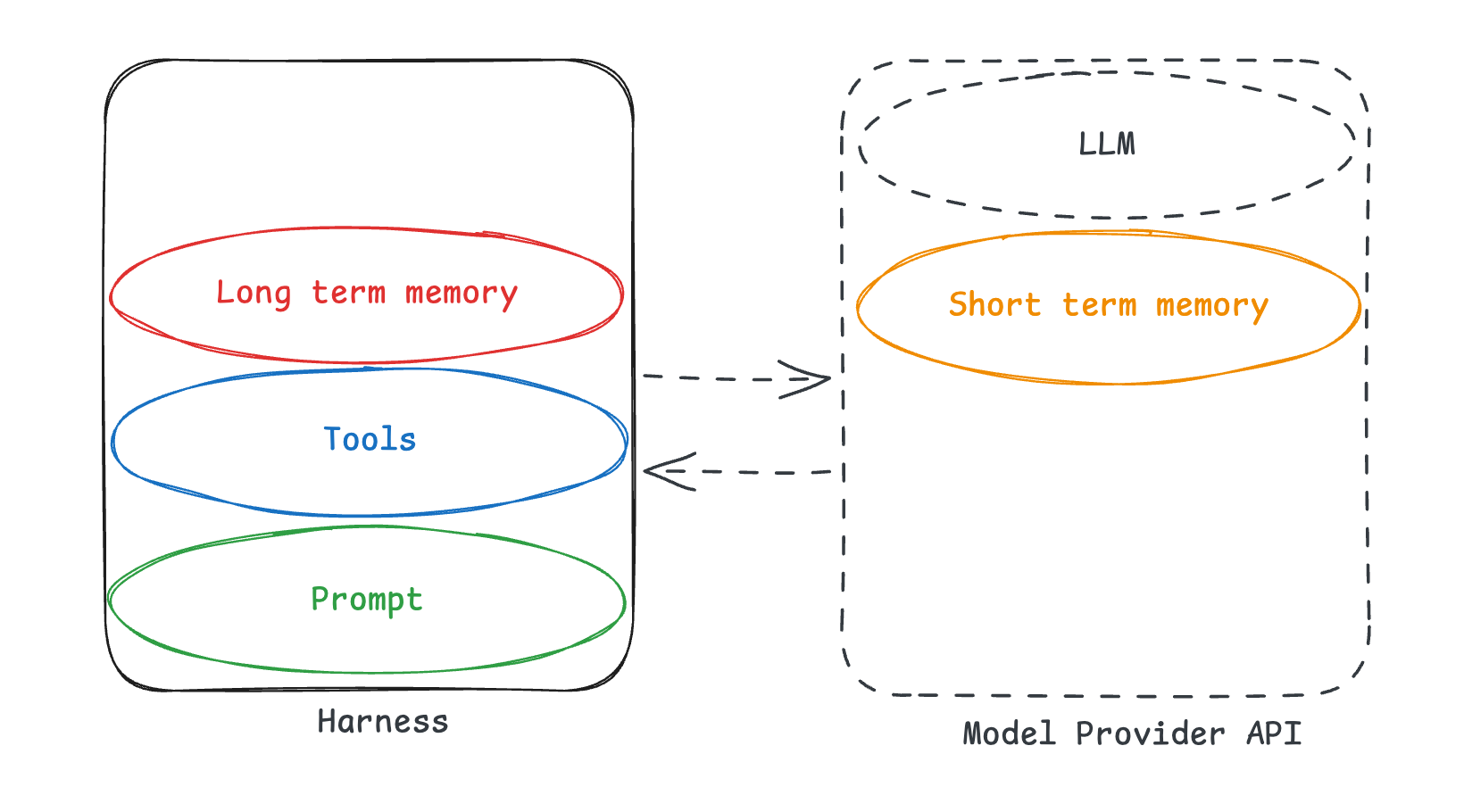
Bad: If you use a closed harness (like Claude Agent SDK, which uses Claude Code under the hood, which is not open source), this harness interacts with memory in a way that is unknown to you. Maybe it creates some artifacts client side - but what is the shape of those, and how should a harness use those? That is unknown, and therefor non-transferrable from one harness to another.
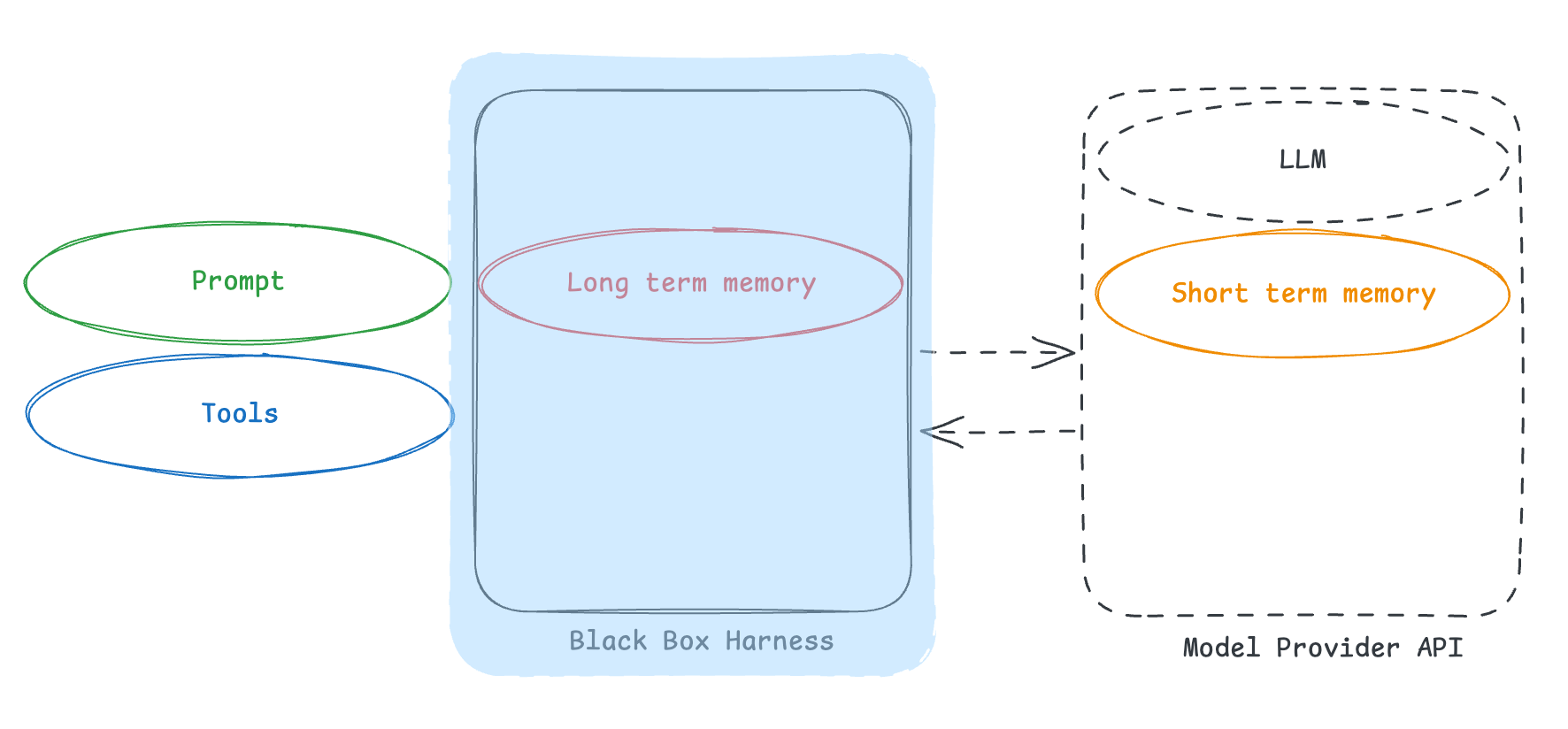
But worst is something else - when the whole harness, including long term memory is behind an API.
In this situation, you have zero ownership or visibility into memory, including long term memory. You do not know the harness (which means you don’t know how to use the memory). But even worse - you don’t even own the memory! Maybe some parts are exposed via API, maybe no parts are - you have no control over that.
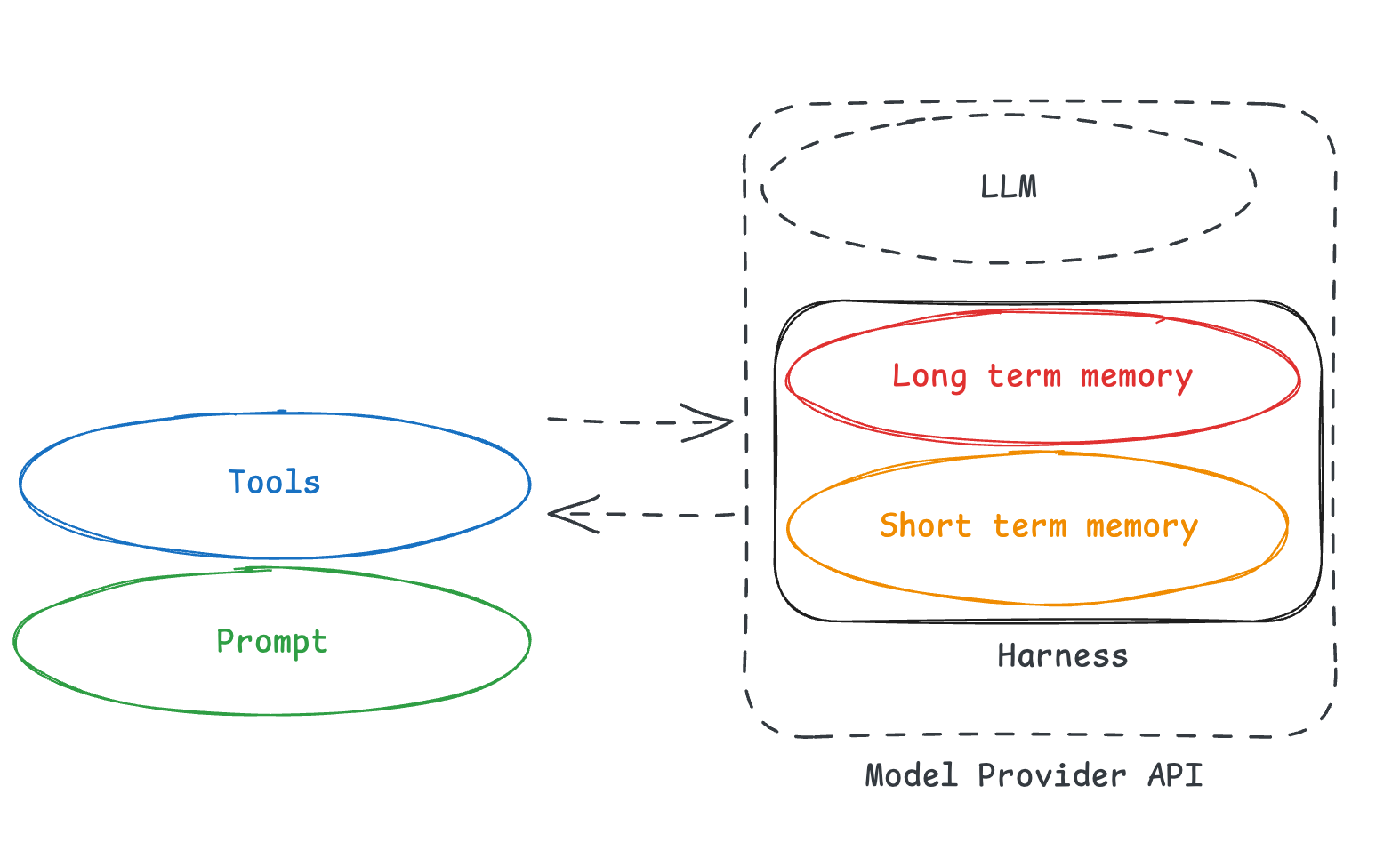
When people say that the “models will absorb more and more of the harness” - this is what they really mean. They mean that these memory related parts will go behind the APIs that model providers offer.
This is incredibly alarming - it means that memory will become locked into a single platform, a single model.
Model providers are incredibly incentivized to do this. And they are starting to. Anthropic launched Claude Managed Agents. This puts literally everything behind an API, locked into their platform.
Even if the whole harness isn’t behind the API, model providers are incentivized to move more and more behind APIs - and are already doing so. For example: even though Codex is an open source, it generates an encrypted compaction summary (that is not usable outside of the OpenAI ecosystem).
Why are they doing this? Because memory is important, and it creates lock in that they don’t get from just the model.
Memory is important, and it creates lock in
Although memory is early, it is clear to everyone that it is important. It is what allows agents to get better as users interact with them, and allows you build up a data flywheel. It is what allows your agent to be personalized to each of your users, and build up an agentic experience that molds to their desires and usage patterns.
Without memory, your agents are easily replicable by anyone who has access to the same tools.
With memory, you build up a proprietary dataset - a dataset of user interactions and preferences. This proprietary dataset allows you to provide a differentiated and increasingly intelligent experience.
It’s been relatively easy to switch model providers to date. They have similar, if not identical, APIs. Sure, you have to change prompts a little bit, but that’s not that hard.
But this is all because they are stateless.
As soon as there is any state associated, its much harder to switch. Because this memory matters. And if you switch, you lose access to it.
Let me tell a story. I have an email assistant internally. It’s built on top of a template in Fleet, our no-code platform for building Enterprise ready OpenClaws. This platform has memory built in, so as I interacted with my email assistant over the past few months it built up memory. A few weeks ago, my agent got deleted by accident. I was pissed! I tried to create an agent from the same template - but the experience was so much worse. I had to reteach it all my preferences, my tone, everything.
The plus side of my email agent deleted - it made me realize how powerful and sticky memory could be.
Open Memory, Open Harnesses
Memory needs to be opened, owned by whomever is developing the agentic experience. It allows you to build up a proprietary dataset that you actually control.
Memory (and therefor harnesses) should be separate from model providers. You should want optionality to try out whatever models are best for your use case. Model providers are incentivized to create lock in via memory.
This is why we are building Deep Agents. Deep Agents:
- Is open source
- Is model agnostic
- Uses open standards like agents.md and skills
- Has plugins to Mongo, Postgres, Redis and others for storing memories
- Is deployable
- via LangSmith Deployment
- Self hostable, can be deployed on any cloud
- Can bring your own database to serve as a memory store
- behind any standard web hosting framework
- via LangSmith Deployment
In order to own your memory, you need to be using an Open Harness
Try out Deep Agents today.
Thank you to a few people for review and thoughts:
- Sydney Runkle, who is doing a lot of great Deep Agents and memory work
- Viv Trivedy, who is a leading voice on agent harnesses
- Nuno Campos, who has some great writing on context engineering for finance agents
- Sarah Wooders, who is CTO of Letta, a company that has consistently been at the forefront of stateful agents