
Header image from Dex Horthy on Twitter.
Context engineering is building dynamic systems to provide the right information and tools in the right format such that the LLM can plausibly accomplish the task.
Most of the time when an agent is not performing reliably the underlying cause is that the appropriate context, instructions and tools have not been communicated to the model.
LLM applications are evolving from single prompts to more complex, dynamic agentic systems. As such, context engineering is becoming the most important skill an AI engineer can develop.
What is context engineering?
Context engineering is building dynamic systems to provide the right information and tools in the right format such that the LLM can plausibly accomplish the task.
This is the definition that I like, which builds upon recent takes on this from Tobi Lutke, Ankur Goyal, and Walden Yan. Let’s break it down.
Context engineering is a system
Complex agents likely get context from many sources. Context can come from the developer of the application, the user, previous interactions, tool calls, or other external data. Pulling these all together involves a complex system.
This system is dynamic
Many of these pieces of context can come in dynamically. As such, the logic for constructing the final prompt needs to be dynamic as well. It is not just a static prompt.
You need the right information
A common reason agentic systems don’t perform is they just don’t have the right context. LLMs cannot read minds - you need to give them the right information. Garbage in, garbage out.
You need the right tools
It may not always be the case that the LLM will be able to solve the task just based solely on the inputs. In these situations, if you want to empower the LLM to do so, you will want to make sure that it has the right tools. These could be tools to look up more information, take actions, or anything in between. Giving the LLM the right tools is just as important as giving it the right information.
The format matters
Just like communicating with humans, how you communicate with LLMs matters. A short but descriptive error message will go a lot further a large JSON blob. This also applies to tools. What the input parameters to your tools are matters a lot when making sure that LLMs can use them.
Can it plausibly accomplish the task?
This is a great question to be asking as you think about context engineering. It reinforces that LLMs are not mind readers - you need to set them up for success. It also helps separate the failure modes. Is it failing because you haven’t given it the right information or tools? Or does it have all the right information and it just messed up? These failure modes have very different ways to fix them.
Why is context engineering important
When agentic systems mess up, it’s largely because an LLM messes. Thinking from first principles, LLMs can mess up for two reasons:
- The underlying model just messed up, it isn’t good enough
- The underlying model was not passed the appropriate context to make a good output
More often than not (especially as the models get better) model mistakes are caused more by the second reason. The context passed to the model may be bad for a few reasons:
- There is just missing context that the model would need to make the right decision. Models are not mind readers. If you do not give them the right context, they won’t know it exists.
- The context is formatted poorly. Just like humans, communication is important! How you format data when passing into a model absolutely affects how it responds
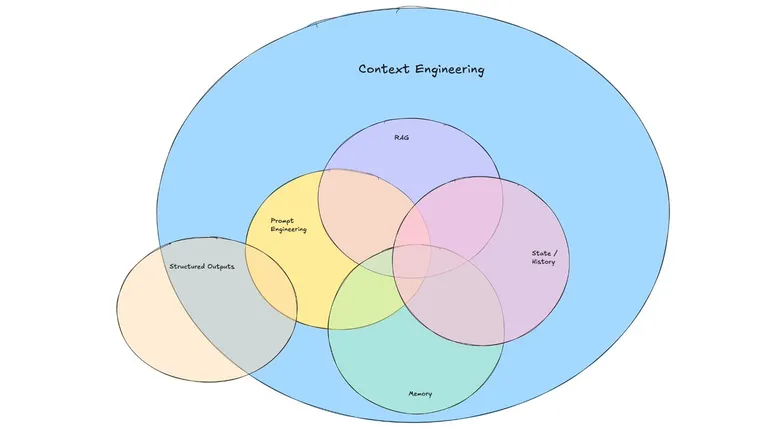
How is context engineering different from prompt engineering?
Why the shift from “prompts” to “context”? Early on, developers focused on phrasing prompts cleverly to coax better answers. But as applications grow more complex, it’s becoming clear that providing complete and structured context to the AI is far more important than any magic wording.
I would also argue that prompt engineering is a subset of context engineering. Even if you have all the context, how you assemble it in the prompt still absolutely matters. The difference is that you are not architecting your prompt to work well with a single set of input data, but rather to take a set of dynamic data and format it properly.
I would also highlight that a key part of context is often core instructions for how the LLM should behave. This is often a key part of prompt engineering. Would you say that providing clear and detailed instructions for how the agent should behave is context engineering or prompt engineering? I think it’s a bit of both.
Examples of context engineering
Some basic examples of good context engineering include:
- Tool use: Making sure that if an agent needs access to external information, it has tools that can access it. When tools return information, they are formatted in a way that is maximally digestable for LLMs
- Short term memory: If a conversation is going on for a while, creating a summary of the conversation and using that in the future.
- Long term memory: If a user has expressed preferences in a previous conversation, being able to fetch that information.
- Prompt Engineering: Instructions for how an agent should behave are clearly enumerated in the prompt.
- Retrieval: Fetching information dynamically and inserting it into the prompt before calling the LLM.
How LangGraph enables context engineering
When we built LangGraph, we built it with the goal of making it the most controllable agent framework. This also allows it to perfectly enable context engineering.
With LangGraph, you can control everything. You decide what steps are run. You decide exactly what goes into your LLM. You decide where you store the outputs. You control everything.
This allows you do all the context engineering you desire. One of the downsides of agent abstractions (which most other agent frameworks emphasize) is that they restrict context engineering. There may be places where you cannot change exactly what goes into the LLM, or exactly what steps are run beforehand.
Side note: a very good read is Dex Horthy's "12 Factor Agents". A lot of the points there relate to context engineering ("own your prompts", "own your context building", etc). The header image for this blog is also taken from Dex. We really enjoy the way he communicates about what is important in the space.
How LangSmith helps with context engineering
LangSmith is our LLM application observability and evals solution. One of the key features in LangSmith is the ability to trace your agent calls. Although the term "context engineering" didn't exist when we built LangSmith, it aptly describes what this tracing helps with.
LangSmith lets you see all the steps that happen in your agent. This lets you see what steps were run to gather the data that was sent into the LLM.
LangSmith lets you see the exact inputs and outputs to the LLM. This lets you see exactly what went into the LLM - the data it had and how it was formatted. You can then debug whether that contains all the relevant information that is needed for the task. This includes what tools the LLM has access to - so you can debug whether it's been given the appropriate tools to help with the task at hand
Communication is all you need
A few months ago I wrote a blog called "Communication is all you need". The main point was that communicating to the LLM is hard, and not appreciated enough, and often the root cause of a lot of agent errors. Many of these points have to do with context engineering!
Context engineering isn't a new idea - agent builders have been doing it for the past year or two. It's a new term that aptly describes an increasingly important skill. We'll be writing and sharing more on this topic. We think a lot of the tools we've built (LangGraph, LangSmith) are perfectly built to enable context engineering, and so we're excited to see the emphasis on this take off.