

By Liam Bush
Background
Every successful platform needs reliable support, but we realized our own team was spending hours tracking down answers to technical questions. This friction wasn't just slowing down our engineers—it was a critical bottleneck for our users.
We set out to solve this using the very tools we champion: LangChain, LangGraph and LangSmith. We originally built chat.langchain.com as a prototype, explicitly designed to serve two functions:
- Product Q&A: Help users—and our own team—get instant, authoritative answers to product questions.
- Customer Prototype: Serve as a living example demonstrating how customers could build sophisticated, reliable agents using the LangChain stack.
We had a strong intent and a functional product. But we have a confession: our support engineers weren't actively using the LangChain Chatbot. That's where our real learning began. This is the story of how we fixed our own agent—and what we learned about building truly reliable, production-grade applications that our customers can adapt and use.
Our team was not actively using Chat LangChain not because it was broken and not because they didn't believe in it. But because when someone asked "Why isn't streaming working in production?" they needed something more thorough than just using docs as it’s only resource. We all know there’s never enough documentation.
So they built their own workflow:
- Step 1: Search our docs (docs.langchain.com) to understand what the feature is supposed to do.
- Step 2: Check our knowledge base (support.langchain.com) to see if other users hit the same issue and how it was resolved.
- Step 3: Open
Claude Code, search the actual implementation, and verify what the code actually does.
Docs for the official story. Knowledge base for real-world issues. Codebase for ground truth.
We Decided to Automate It
This three-step ritual worked incredibly well. We watched them do it dozens of times a day and thought: what if we just automated this exact workflow?
So we built an internal Deep Agent (a library for building agents that can tackle complex, multi-step tasks) with three specialized subagents — one for docs, one for knowledge base, one for codebase search — each one asking follow-up questions and filtering results before passing insights to a main orchestrator agent.
The main agent would synthesize everything and deliver answers like this:
Example output:
"To stream from subgraphs, set subgraphs: true in your stream config according to the LangGraph streaming docs. There's a support article titled ['Why is token streaming not working after upgrade](https://support.langchain.com/articles/7150806184-Why-is-token-by-token-streaming-not-working-after-upgrading-LangGraph?)[?](https://www.notion.so/263808527b1780db9f26fa75aed5e7e3?pvs=21)' that explains this exact issue — you need to enable subgraph streaming to get token-level updates from nested agents. The implementation is in pregel/main.py lines 3373-3279, where the subgraphs flag controls whether nested graph outputs are included in the stream."
Our engineers loved it.
It saved them hours every week on complex debugging. They'd describe a production issue and get back a comprehensive answer that cited documentation, referenced known solutions, and pointed to the exact lines of code that mattered.
Then We Had a Realization
Then someone asked the obvious question: if this works so well for us, why doesn't our public Chat LangChain work this way?
It was a fair point. Our public tool was chunking documents into fragments, generating embeddings, storing them in a vector database. We had to reindex constantly as docs updated. Users got answers, but the citations needed love and the context was fragmented.
We'd accidentally built something better internally just by copying what worked. It was time to bring that same approach to the public product.
When we started rebuilding, we quickly realized we needed to combine two different architectures driven by two broad categories of questions. Most questions could be answered using docs and knowledge base. The remainder would require analysis of foundation of code.
How We Built The New Agent
For Simple Docs: Create Agent
We chose createAgent (Agent abstraction in langchain) for chat.langchain.com as the default mode because it's best for speed.
There's no planning phase, no orchestration overhead — just immediate tool calls and answers. The agent searches the docs, checks the knowledge base if needed, refines its query if the results are unclear, and returns an answer. Most documentation questions can be handled with 3-6 tool calls, and Create Agent executes those in seconds.
Model options:
We give end-users access to multiple models — Claude Haiku 4.5, GPT-4o Mini, and GPT-4o-nano — and we've found that Haiku 4.5 is exceptionally fast at tool calling while maintaining strong accuracy. The combination of createAgent and Haiku 4.5 delivers sub-15-second responses for most queries, which is exactly what documentation Q&A demands.
How we optimized it:
We used LangSmith to trace every conversation, identify where the agent was making unnecessary tool calls, and refine our prompts. The data showed us that most questions could be answered with 3-6 tool calls if we taught the agent to ask better follow-up questions. LangSmith's evaluation suite let us A/B test different prompting strategies and measure improvements in both speed and accuracy.
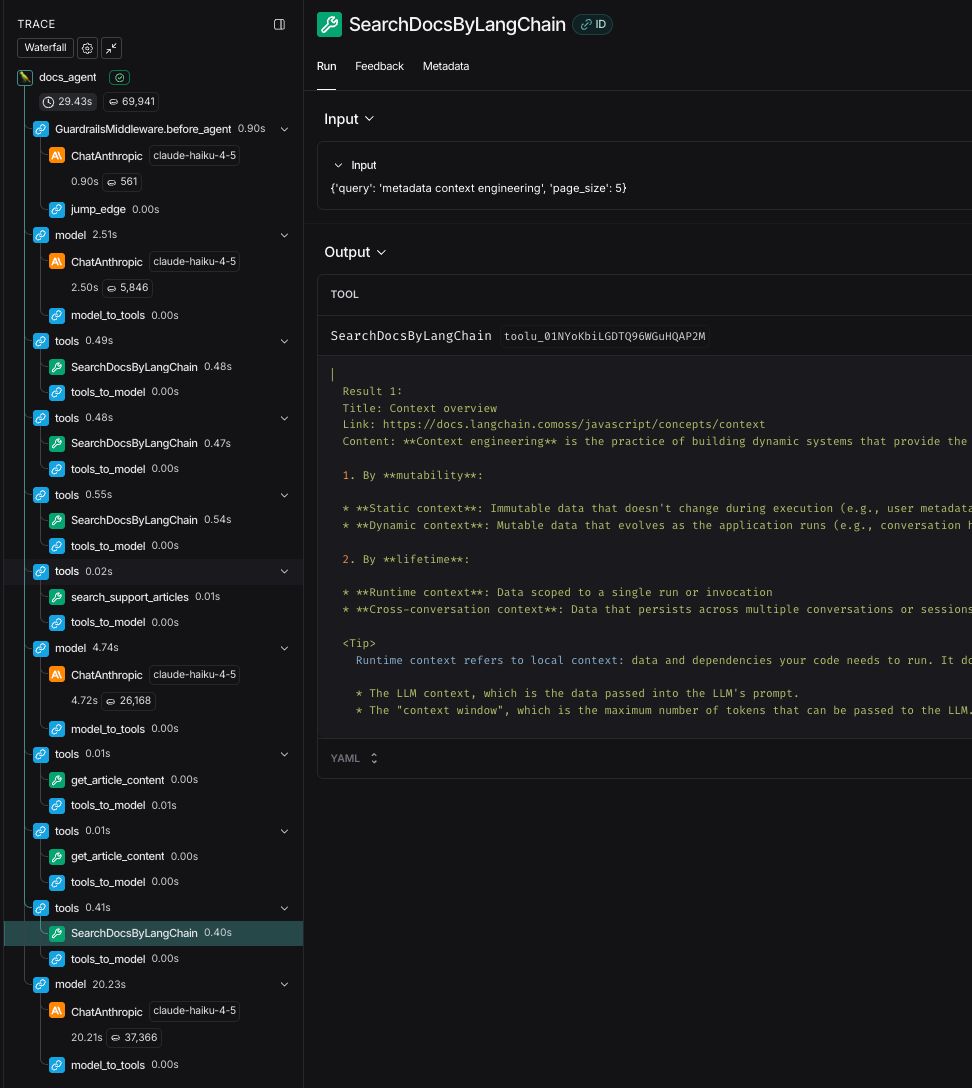
For answering using code: Deep Agent with Subgraphs
A lot of questions needed searching diving into our codebases to verify implementation details in addition to leveraging documentation, knowledge bases and cross-referencing known issues as resources.
The architecture:
For these tasks, we built a Deep Agent with specialized subgraphs: one for documentation search, one for knowledge base search, and one for codebase search.
Each subagent operates independently, asking follow-up questions, filtering through information, and extracting only the most relevant insights before passing them up to a main orchestrator agent. This prevents the main agent from drowning in context while allowing each domain expert to dig as deep as necessary.
The codebase search advantage:
The codebase search subagent is particularly powerful. It can search our private repositories using pattern matching, navigate file structures to understand context, and read specific implementations with line-number precision.
The tradeoff:
This deep agent architecture takes longer to run — sometimes 1-3 minutes for complex queries — but the thoroughness is worth it. We leverage DeepAgent when the initial response is not addressing the core question.
Disclaimer: This mode is only enabled for a subset of users at launch and will be made generally available in a few days.
Why We Got Moved Away from Vector Embeddings
The standard approach to documentation search — chunk docs into pieces, generate embeddings, store in a vector database, retrieve by similarity — works fine for unstructured content like PDFs. But for structured product documentation, we kept hitting three problems.
Chunking breaks structure. When you chop documentation into 500-token fragments, you lose headers, subsections, and context. The agent would cite "set streaming=True" without explaining why or when. Users had to hunt through pages to find what they needed.
Constant reindexing. Our docs update multiple times daily. Every change meant re-chunking, re-embedding, and re-uploading. It slowed us down.
Vague citations. Users couldn't verify answers or trace where information came from.
The breakthrough was realizing we were solving the wrong problem. Documentation is already organized. Knowledge bases are already categorized. Codebases are already navigable. We didn't need smarter retrieval — we needed to give the agent direct access to that existing structure.
The Better Approach: Direct API Access and Smart Prompting
Instead of chunking and embedding, we gave the agent direct access to the real thing. For documentation, we use Mintlify's API, which returns full pages with all their headers, subsections, and code examples intact. For the knowledge base, we query our support articles by title first, then read the most promising ones in full. For codebase search, we uploaded our codebase to our LangGraph Cloud deployment and use ripgrepfor pattern matching, directory traversal to understand structure, and file reading to extract specific implementations.
The agent doesn't retrieve based on similarity scores. It searches like a human would — with keywords, refinement, and follow-up questions.
This is where the magic happens. We don't just tell the agent to search once and return whatever it finds. We prompt it to think critically about whether it has enough information. If the results are ambiguous or incomplete, the agent refines its query and searches again. If documentation mentions a concept without explaining it, the agent searches for that concept specifically. If multiple interpretations are possible, the agent narrows down to the most relevant one.
Tool Design: Building for Human Workflows
We designed our tools to mirror how humans actually search, not how retrieval algorithms work.
Documentation Search: Full Pages, Not Fragments
The documentation search tool queries Mintlify's API and returns complete pages. When someone asks about streaming, the agent doesn't get three disjointed paragraphs from different sections — it gets the entire streaming documentation page, structured exactly as a human would read it.
@tool
def SearchDocsByLangChain(query: str, page_size: int = 5, language: Optional[str] = None) -> str:
"""Search LangChain documentation via Mintlify API"""
params = {"query": query, "page_size": page_size}
if language:
params["language"] = language
response = requests.get(MINTLIFY_API_URL, params=params)
return _format_search_results(response.json())
But we don't stop there. We prompt the agent to evaluate whether the initial results actually answer the question. Is this the right section? Are there related concepts that need clarification? Would a more specific search term be better?
The agent has a budget of 4-6 tool calls, and we encourage it to use them strategically to refine its understanding before responding.
Here's what that looks like in practice:
A user asks, "How do I add memory to my agent?"
The agent searches for "memory" and gets results that cover checkpointing, conversation history, and the Store API. Instead of picking one at random, the agent realizes the question is ambiguous — memory could mean persisting conversation state within a thread or storing facts across multiple conversations.
It searches again with "checkpointing" to narrow down thread-level persistence, fetches the support article "How do I configure checkpointing in LangGraph?" and recognizes it doesn't cover cross-thread memory.
So it searches for "store API" to fill the gap.
The final answer covers both checkpointing for conversation history and the Store API for long-term memory, with precise citations to the support article and documentation used.
This iterative search process happens in seconds with Create Agent, but it fundamentally changes the quality of responses. The agent isn't just retrieving — it's reasoning about what the user actually needs.
Knowledge Base Search: Scan, Then Read
We built the knowledge base (powered by Pylon) search as a two-step process because that's how humans use knowledge bases.
First, the agent retrieves article titles — sometimes dozens of them — and scans them to identify which ones seem relevant. Then it reads only those articles in full.
@tool
def search_support_articles(collections: str = "all", limit: int = 50) -> str:
"""Step 1: Get article titles to scan"""
articles = pylon_client.list_articles(collections=collections, limit=limit)
return json.dumps([{
"id": a["id"],
"title": a["title"],
"url": a["url"]
} for a in articles])
@tool
def get_article_content(article_ids: List[str]) -> str:
"""Step 2: Read the most relevant articles"""
articles = pylon_client.get_articles(article_ids)
return "\\n\\n---\\n\\n".join([
f"# {a['title']}\\n\\n{a['content']}\\n\\nSource: {a['url']}"
for a in articles
])
Why this works:
This prevents the agent from drowning in information. Instead of passing 30 full articles to the context window, the agent filters down to the 2-3 that actually matter, reads them thoroughly, and extracts the key insights.
The prompting reinforces this: focus on quality over quantity, narrow your search if needed, and return only the information that directly answers the question.
Codebase Search: Search, Navigate, Verify
This is where our Deep Agent shines.
We gave the agent three tools that mirror the workflow from the opening — the same pattern our engineers follow when using Claude Code:
@tool
def search_public_code(pattern: str, path: Optional[str] = None) -> str:
"""Step 1: Find code matching a pattern"""
cmd = ["rg", pattern, str(path or search_path)]
return subprocess.run(cmd, capture_output=True, text=True).stdout
@tool
def list_public_directory(path: str, max_depth: int = 2) -> str:
"""Step 2: Understand the file structure"""
cmd = ["tree", "-L", str(max_depth), str(path)]
return subprocess.run(cmd, capture_output=True, text=True).stdout
@tool
def read_public_file(file_path: str, start_line: int = 1, num_lines: int = 100) -> str:
"""Step 3: Read the actual implementation"""
with open(file_path, "r") as f:
lines = f.readlines()
return "\\n".join(lines[start_line-1:start_line-1+num_lines])
How it works:
First, it searches the codebase for a pattern using ripgrep. Then it lists the directory structure to understand how files are organized. Finally, it reads the specific file, focusing on the relevant section, and returns the implementation with line numbers.
Real-world example:
A user reports that streaming tokens hang in production. The docs subagent finds that streaming configuration involves buffer settings. The knowledge base subagent surfaces a support article about token streaming issues after upgrades.
But the codebase subagent is the one that finds the actual implementation — it searches for "streaming buffer", navigates to callbacks/streaming.py, and returns lines 47-83 where the default buffer size is hardcoded.
That's the kind of deep investigation that solves real problems.
The difference? The Deep Agent can work in parallel across all three domains, and summarize the interim findings into one coherent answer.
How Deep Agent and Subgraphs Solve Context Overload
When we first built the deep agent as a single system with access to all three tools, it would return everything it found. The main agent would get five documentation pages, twelve knowledge base articles, and twenty code snippets — all at once.
The context window would explode, and the final response would either be bloated with irrelevant details or miss the key insight entirely.
That's when we restructured it with specialized subgraphs.
How it works:
Each subagent operates independently. It searches its domain, asks follow-up questions to clarify ambiguity, filters through the results, and extracts only the golden data: the essential facts, citations, and context needed to answer the question.
The main orchestrator agent never sees the raw search results. It only receives the refined insights from each domain expert. Look at a full trace along with prompts **here.
Why this matters:
The docs subagent might read five full pages but return only two key paragraphs. The knowledge base subagent might scan twenty article titles but return only three relevant summaries. The codebase subagent might search fifty files but return only the specific implementation with line numbers.
The main agent gets clean, curated information that it can synthesize into a comprehensive answer.
Making It Production-Ready
Even elegant agent designs need production infrastructure to survive contact with real users. We built modular middleware to handle the operational concerns that would otherwise clutter our prompts.
middleware = [
guardrails_middleware, # Filter off-topic queries
model_retry_middleware, # Retry on API failures
model_fallback_middleware, # Switch models if needed
anthropic_cache_middleware # Cache expensive calls
]
What each layer does:
Guardrails filter out off-topic queries so the agent stays focused on LangChain questions.
Retry middleware handles temporary API failures gracefully, so users never see cryptic error messages.
Fallback middleware switches between Haiku, GPT-4o Mini, and Gemini Nano if a model is unavailable.
Caching reduces costs by reusing results for identical queries.
These layers are invisible to users, but they're essential for reliability. They let the agent focus on reasoning while the infrastructure handles failure modes, cost optimization, and quality control.
Getting the Agent to Users
Building a great agent is only half the battle. The other half? Getting it to users in a way that feels fast and intelligent.
We use the LangGraph SDK to handle all the complexity of streaming and state management.
Loading User Threads:
When someone opens Chat LangChain, we fetch their conversation history using the LangGraph SDK:
const userThreads = await client.threads.search({
metadata: { user_id: userId },
limit: THREAD_FETCH_LIMIT,
})
Every thread stores the user's ID in metadata, so conversations stay private and persistent across sessions. The LangGraph SDK handles the filtering automatically.
Streaming Responses in Real Time:
When a user sends a message, the LangGraph SDK streams the response as it generates:
typescript
const streamResponse = client.runs.stream(threadId, "docs_agent", {
input: { messages: [{ role: "user", content: userMessage }] },
streamMode: ["values", "updates", "messages"],
streamSubgraphs: true,
})
for await (const chunk of streamResponse) {
if (chunk.event === "messages/partial") {
setMessages(prev => updateWithPartialContent(chunk.data.content))
}
}
What users see:
Three stream modes show the agent's entire thought process:
messages— Tokens appear progressively as the agent writesupdates— Tool calls reveal what the agent is searchingvalues— Final complete state after processing
Users watch the agent think, search docs, check the knowledge base, and build the response token-by-token. No loading spinners.
Conversation Memory
Pass the same thread_id across messages and LangGraph's checkpointer handles the rest. It stores conversation history, retrieves context for each turn, and maintains state across sessions. We set a 7-day TTL. That's it.
The Results
Since launching the new systems, we've seen dramatic improvements.
For public Chat LangChain, users get sub-15-second responses with precise citations. They can verify answers immediately because we link directly to the relevant documentation page or knowledge base article. And we no longer spend hours reindexing — the documentation updates automatically.
Internally, our support engineers use the Deep Agent to handle the most complex tickets. It searches documentation, cross-references known issues, and dives into our private codebase to find the implementation details that actually explain what's happening. The agent doesn't replace our engineers — it amplifies them, handling the research so they can focus on solving the problem.
Key Takeaways
- Follow the user's workflow: Don't reinvent the wheel; automate the successful workflow your best users (or internal experts) already use. For LangChain, this meant replicating the three-step ritual of checking docs, the knowledge base, and the codebase.
- Evaluate if vector embeddings are appropriate: For structured content like product documentation and code, using vector embeddings could break the document structure, leads to vague citations, and requires constant reindexing. Vector embeddings are fantastic for unstructured content or shorter blocks or clustering use cases.
- Give the agent direct access to structure: This approach allows the agent direct API access to the content's existing structure. This allows the agent to search like a human, with keywords and refinement.
- Prioritize reasoning over retrieval: Design tools to mirror human workflows: scan article titles then read content, and use pattern matching and directory navigation for code. Prompt the agent to ask follow-up questions and refine its query if initial results are ambiguous, ensuring the final answer covers the user's real need.
- Use Deep Agents and subgraphs to manage context: For complex, multi-domain questions, using a Deep Agent with specialized subgraphs prevents the main orchestrator agent from drowning in raw search results. Each subagent filters and extracts only the "golden data" from its domain before passing the refined insights up.
- The need for production middleware: Even an elegant agent design needs robust infrastructure to be reliable. Implementing modular middleware for guardrails (filtering off-topic queries), retries (on API failures), fallbacks (switching models), and caching is essential for production-grade reliability, cost-optimization, and quality control.
What's Next
Public codebase search (launching in the next few days) — When docs and knowledge base aren't sufficient, the agent will search our public repositories to verify implementations and cite exact line numbers
Try It Yourself
Chat LangChain is live at chat.langchain.com. Try it with Claude Haiku 4.5 for the fastest responses, or experiment with GPT-5 Mini and GPT-5 Nano to see how different models perform.
Join the Conversation
Building agents that balance speed and depth is hard, and we're still learning. If you're working on similar problems, we'd love to hear what you're discovering.
Join the LangChain community on our forum or follow us on Twitter.
Subscribe to our newsletter for updates from the team and community.