

Over the past few weeks, we’ve been running open weight Large Language Models through Deep Agents harness evaluations, and the initial results show they are a viable option to use instead of, and alongside, closed frontier models. GLM-5 (z.ai) and MiniMax M2.7 each score similarly to closed frontier models on core agent tasks such as file operations, tool use, and instruction following.
This isn’t surprising if you’ve been following open model progress via the large set of open benchmarks such as SWE-Rebench and Terminal Bench 2.0. Tool calling is reliable and instruction following is consistent. For developers deploying agents in production, open models now offer a level of consistency and predictability that makes real-world workflows much more viable.
Why open models
When exploring open models, builders and customers tend to focus on a few key factors: cost, latency, and task performance.
In the limit, it would be great to use the smartest frontier model at the highest reasoning level for every task. In practice, two constraints make that unworkable: cost and latency. Closed frontier models can run 8–10x more expensive for high-throughput workloads, and they're often too slow for the response times users expect in interactive products.
| Model | Type | Input ($/M tokens) | Output ($/M tokens) |
|---|---|---|---|
| Claude Opus 4.6 (Anthropic) | Closed | $5.00 | $25.00 |
| Claude Sonnet 4.6 (Anthropic) | Closed | $3.00 | $15.00 |
| GPT-5.4 (OpenAI) | Closed | $2.50 | $15.00 |
| GLM-5 (Baseten) | Open | $0.95 | $3.15 |
| MiniMax M2.7 (OpenRouter) | Open | $0.30 | $1.20 |
To put the pricing in context: an application outputting 10M tokens/day costs roughly $250/day on Opus 4.6 versus ~$12/day for MiniMax M2.7. That's about a $87k annual difference.
Open models tend to be smaller than closed frontier models, and can be accelerated on specialized inference infrastructure — providers like Groq, Fireworks, and Baseten optimize for latency and throughput far beyond what most teams could achieve on their own. OpenRouter data show GLM-5 on Baseten averaging 0.65s latency and 70 tokens/second, compared to 2.56s and 34 tokens/second for Claude Opus 4.6. For latency-sensitive products, that gap is hard to engineer around.
How we evaluated
We've written about our eval methodology in depth in How we build evals for Deep Agents. We run evals using hosted inference providers, but Deep Agents can be run using fully local and private models via Ollama, vLLM, etc.
For open models, we ran seven eval categories: file operations, tool use, retrieval, conversation, memory, summarization, and “unit tests”. These cover tasks that exercise fundamentals: can the model reliably call tools, follow structured instructions, and operate on files? These are the capabilities that gate whether a model is usable in an agentic harness at all.
Each eval case defines success assertions (hard-fail checks that determine correctness) and efficiency assertions (soft checks that measure how the model got there). We report four metrics:
- Correctness — the fraction of tests the model solved:
passed / total. A score of 0.68 means 68% of test cases were solved correctly. This is the primary quality signal. - Solve rate — a combined measure of accuracy and speed. For each test, we compute
expected_steps / wall_clock_seconds; failed tests contribute zero. The final score is the average across all tests. Higher is better — a model that solves tasks both correctly and quickly scores highest. - Step ratio — how many agentic steps the model actually took compared to how many we expected, aggregated across all tests:
total_actual_steps / total_expected_steps. A value of 1.0 means the model used exactly the expected number of steps. Above 1.0 means it needed more (less efficient); below 1.0 means it needed fewer steps than initially expected. - Tool call ratio — same idea as step ratio, but counting individual tool calls instead of steps. 1.0 is on-budget, above is over-budget, below is under-budget.
Step ratio and tool call ratio are efficiency metrics. They don't affect whether a test passes, but they reveal how economically a model reaches the answer. A model that solves a task in 2 steps instead of the expected 5 is both correct and efficient.
Findings from our evals
These are early results; we’re actively maintaining and expanding our eval set. You can view recent runs in realtime both in our GitHub repo and at this shared LangSmith project.
Open models
View CI run (click model names to view individual evals)
| Model | Correctness | Passed | Solve Rate | Step Ratio | Tool Call Ratio |
|---|---|---|---|---|---|
| baseten:zai-org/GLM-5 | 0.64 | 94 of 138 | 1.17 | 1.02 | 1.06 |
| ollama:minimax-m2.7 | 0.57 | 85 of 138 | 0.27 | 1.02 | 1.04 |
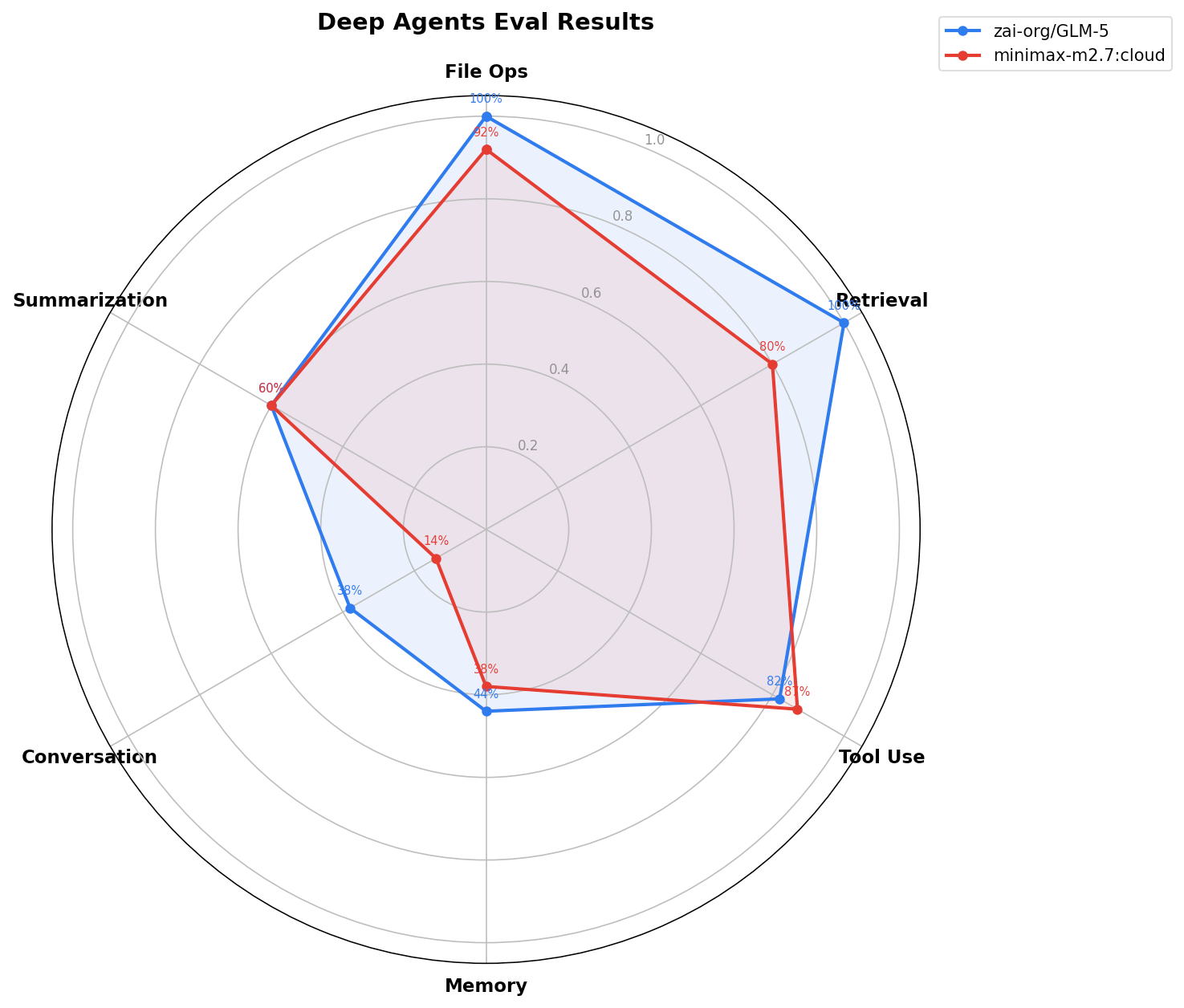
Per-category correctness:
| model | Conversation | File Ops | Memory | Retrieval | Summarization | Tool Use | Unit Test |
|---|---|---|---|---|---|---|---|
| baseten:zai-org/GLM-5 | 0.38 | 1 | 0.44 | 1 | 0.6 | 0.82 | 1 |
| ollama:minimax-m2.7:cloud | 0.14 | 0.92 | 0.38 | 0.8 | 0.6 | 0.87 | 0.92 |
Frontier models
View CI run (click model names to view individual evals)
| Model | Correctness | Passed | Solve Rate | Step Ratio | Tool Call Ratio |
|---|---|---|---|---|---|
| anthropic:claude-opus-4-6 | 0.68 | 100 of 138 | 0.38 | 0.99 | 1.02 |
| google_genai:gemini-3.1-pro-preview | 0.65 | 96 of 138 | 0.26 | 0.99 | 1.01 |
| openai:gpt-5.4 | 0.61 | 91 of 138 | 0.61 | 1.05 | 1.15 |
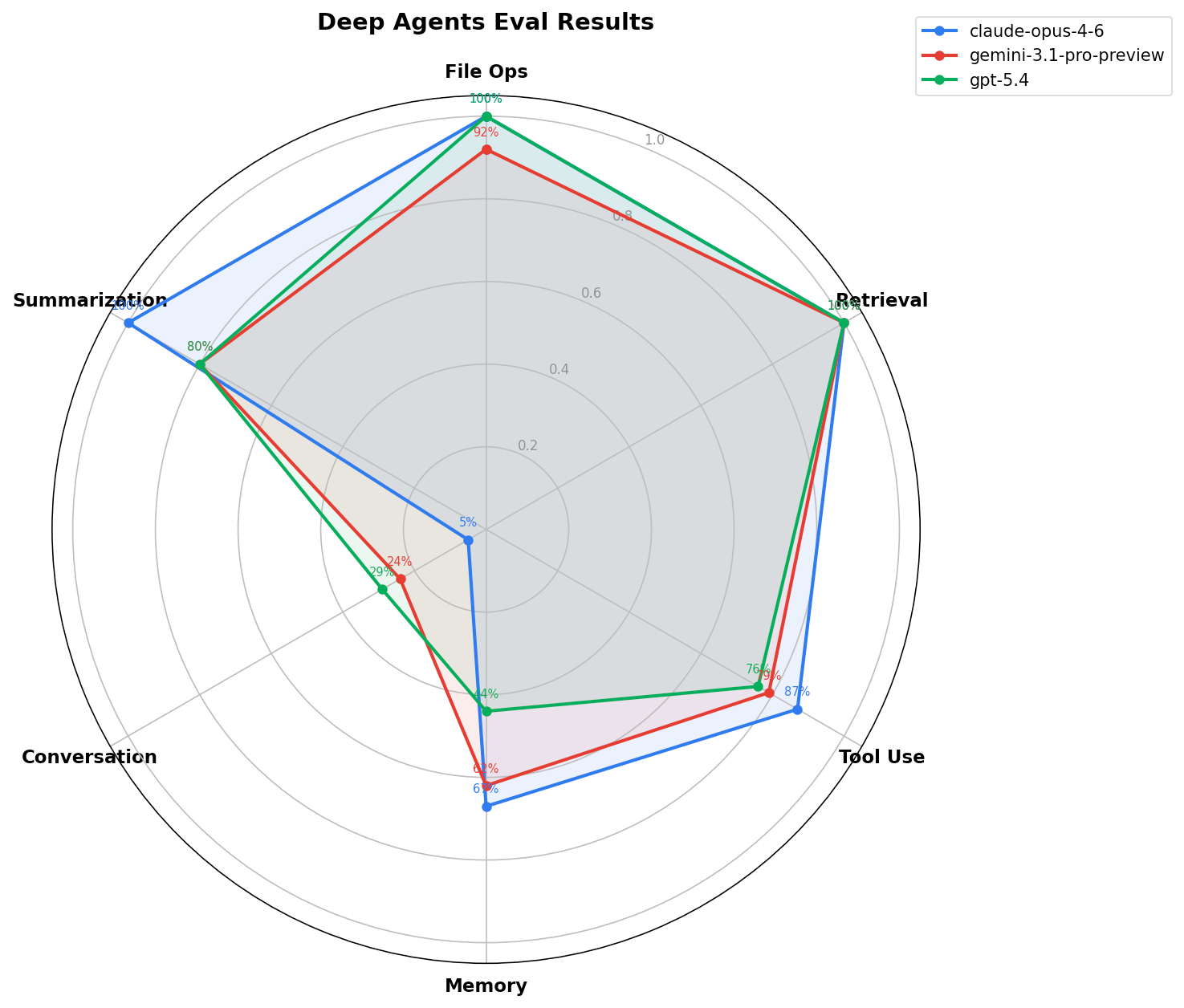
Per-category correctness:
| model | Conversation | File Ops | Memory | Retrieval | Summarization | Tool Use | Unit Test |
|---|---|---|---|---|---|---|---|
| anthropic:claude-opus-4-6 | 0.05 | 1 | 0.67 | 1 | 1 | 0.87 | 1 |
| google_genai:gemini-3.1-pro-preview | 0.24 | 0.92 | 0.62 | 1 | 0.8 | 0.79 | 0.92 |
| openai:gpt-5.4 | 0.29 | 1 | 0.44 | 1 | 0.8 | 0.76 | 1 |
For Gemini 3+, this is
highFor OpenAI, this is
mediumFor Claude, this is without extended thinking
DIY: Run Deep Agent evals locally
Our CI runs the same evaluation suite across 52 models organized into groups — including an open group (baseten:zai-org/GLM-5, ollama:minimax-m2.7:cloud, ollama:nemotron-3-super) that runs on every eval workflow. You can target any model group:
Run evals against all open models: pytest tests/evals --model-group open
Run against a specific model: pytest tests/evals --model baseten:zai-org/GLM-5
This makes it straightforward to compare open models against each other and against closed frontier models on the same tasks, using the same grading criteria.
Using open models in Deep Agents SDK
Swapping to an open model is a one-line change:
GLM-5:
# pip install langchain-baseten
from deepagents import create_deep_agent
agent = create_deep_agent(model="baseten:zai-org/GLM-5")
MiniMax M2.7:
# pip install langchain-openrouter
from deepagents import create_deep_agent
agent = create_deep_agent(model="openrouter:minimax/minimax-m2.7")
That's it. The harness handles the rest — it detects the model's context window size, disables unsupported modalities, and injects the right identity into the system prompt so the agent knows what it's working with.
The same open model is often available through multiple providers. Pick the one that matches your constraints. For example, GLM-5 is available as baseten:zai-org/GLM-5, fireworks:fireworks/glm-5, or ollama:glm-5 for self-hosted. Same model, same harness, different infrastructure.
LangChain provides support for the most popular open model providers. The providers we have tested for this release are: Baseten, Fireworks, Groq, OpenRouter, and Ollama (cloud).
Harness-level adjustments for your model
Open models have different context windows, different tool-calling formats, and different failure modes than closed frontier models. The Deep Agents harness absorbs these differences so you don't have to:
- Model identity injection — the system prompt is patched at runtime with the model's name, provider, context limit, and supported modalities. The agent knows what it is and what it can do.
- Context management — compression, offloading, and summarization thresholds adapt to the model's actual context window, not a hardcoded default. A model with a 4K context gets more aggressive compaction than Opus with 1M.
Deep Agents CLI
Each model is also available in the Deep Agents CLI. The Deep Agents CLI is our open-source coding agent and alternative to Claude Code.
In addition to all the capabilities in Deep Agents SDK, the CLI supports Runtime model swapping. We introduced a new middleware (ConfigurableModelMiddleware ) to enable switching models mid-session without restarting the agent. This enables patterns like using a frontier model for planning and an open model for execution.
You can switch models mid-session with the /model slash command. This enables patterns like starting a task with a frontier model for planning, then switching to a cheaper open model for execution.
What’s next
Some things we’re excited to share soon:
- Documenting harness tuning patterns for specific open model families
- Testing multi-model subagent configurations (ex: frontier closed model orchestrator + open model subagents)
Open models work for agents today. We want to show the design patterns that help us engineer a good harness and build targeted evals that measure what matters for your task.
Deep Agents is open source. Try it with your preferred open model and come build great evals and agents with us.