

TL;DR
Deep research has broken out as one of the most popular agent applications. OpenAI, Anthropic, Perplexity, and Google all have deep research products that produce comprehensive reports using various sources of context. There are also many open source implementations.
We've built an open deep researcher that is simple and configurable, allowing users to bring their own models, search tools, and MCP servers.
- Open deep research is built on LangGraph. See the code here!
- Try it out on Open Agent Platform
Challenge
Research is an open‑ended task; the best strategy to answer a user request can’t be easily known in advance. Requests can require different research strategies and varying levels of search depth.
“Compare these two products”
Comparisons typically benefit from a search on each product, followed by a synthesis step to compare them.
“Find the top 20 candidates for this role”
Listing and ranking requests typically require open-ended search, followed by a synthesis and ranking.
“Is X really true?”
Validation questions can require iterative deep research into a specific domain, where the quality of sources matters much more than the breadth of the search.
With these points in mind, a key design principle for open deep research is flexibility to explore different research strategies depending on the request.
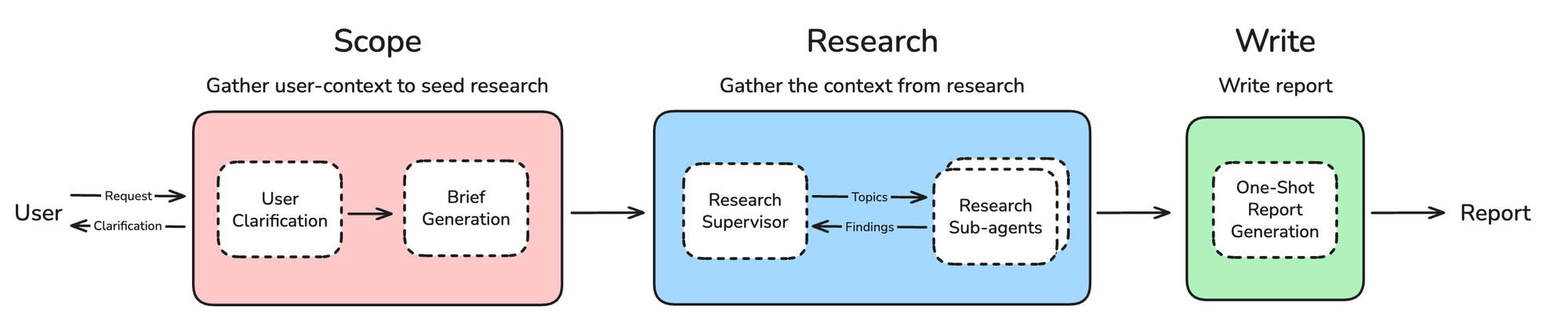
Architectural Overview
Agents are well suited to research because they can flexibly apply different strategies, using intermediate results to guide their exploration. Open deep research uses an agent to conduct research as part of a three step process:
- Scope – clarify research scope
- Research – perform research
- Write – produce the final report
Phase 1: Scope
The purpose of scoping is to gather all user-context needed for research. This is a two-step pipeline that performs User Clarification and Brief Generation.
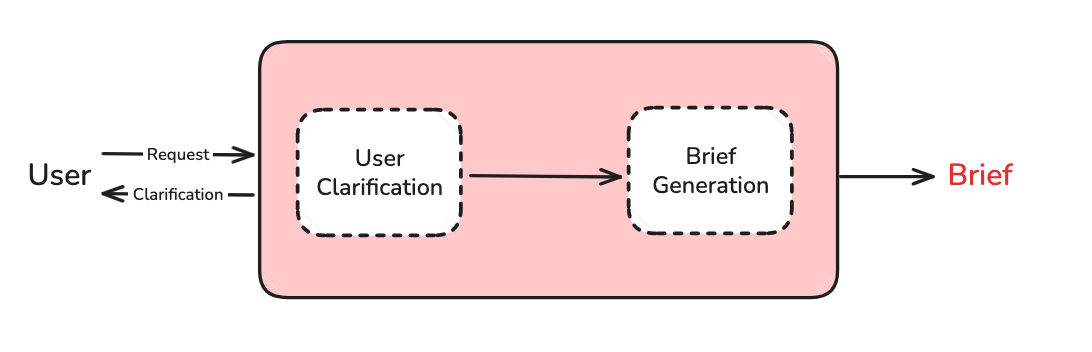
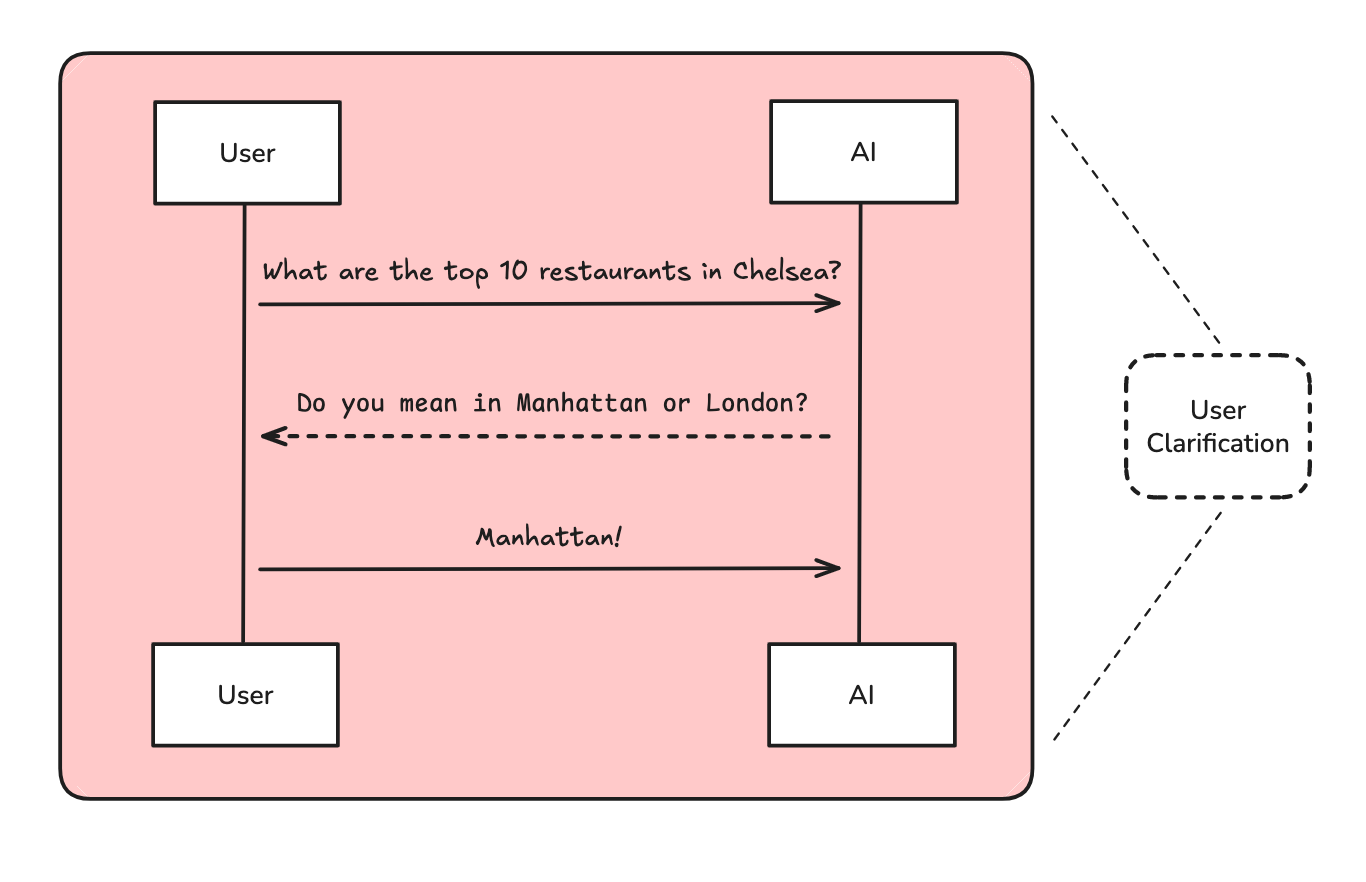
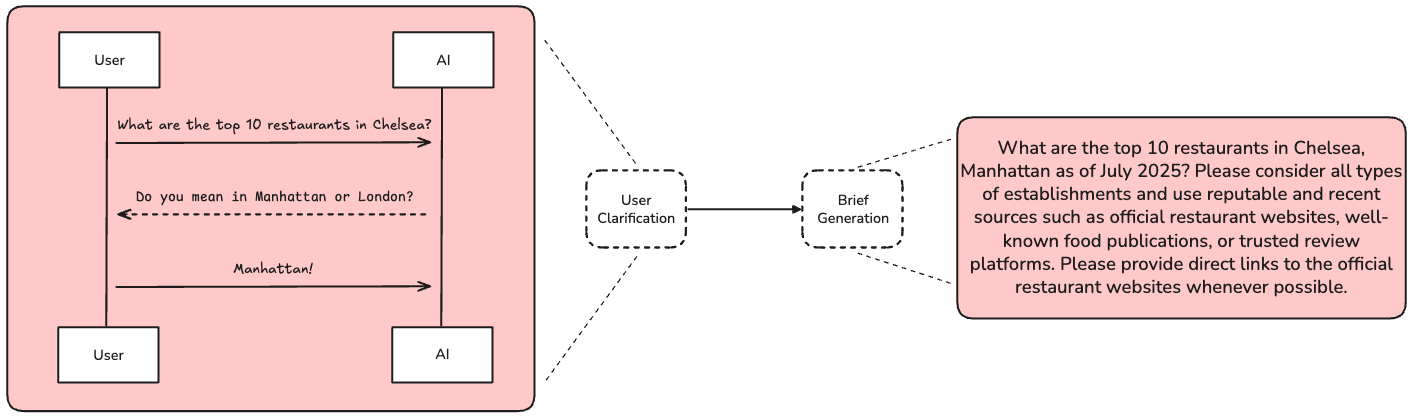
User Clarification
OpenAI has made the point that users rarely provide sufficient context in a research request. We use a chat model to ask for additional context if necessary.
Brief Generation
The chat interaction can include clarification questions, follow-ups, or user-provided examples (e.g., a prior deep research report). Because the interaction can be quite verbose and token-heavy, we translate it into a comprehensive, yet focused research brief. The research brief serves as our north star for success, and we refer back to it throughout the research and writing phases.
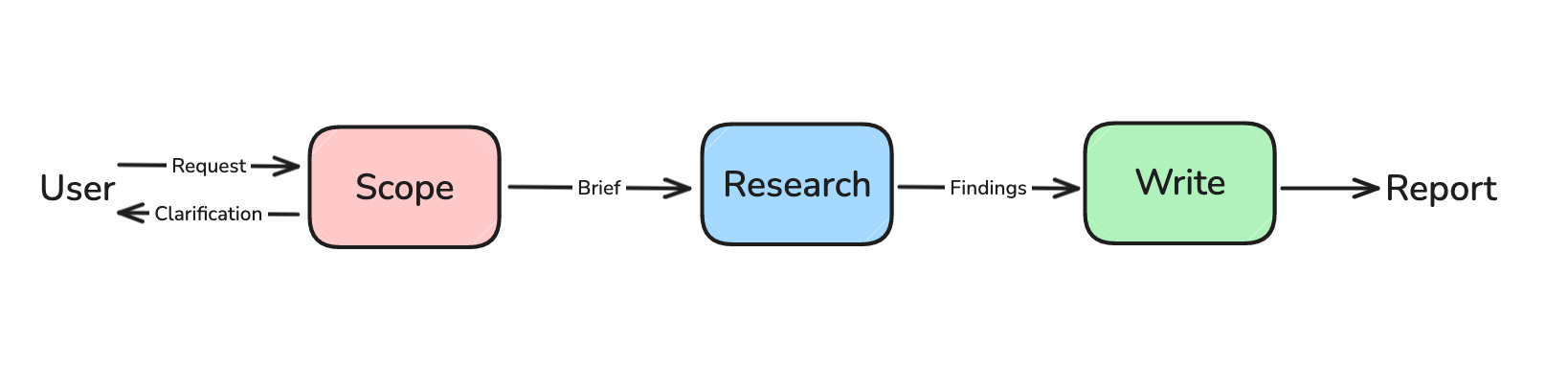
Phase 2: Research
The goal of research is to gather the context requested by the research brief. We conduct research using a supervisor agent.
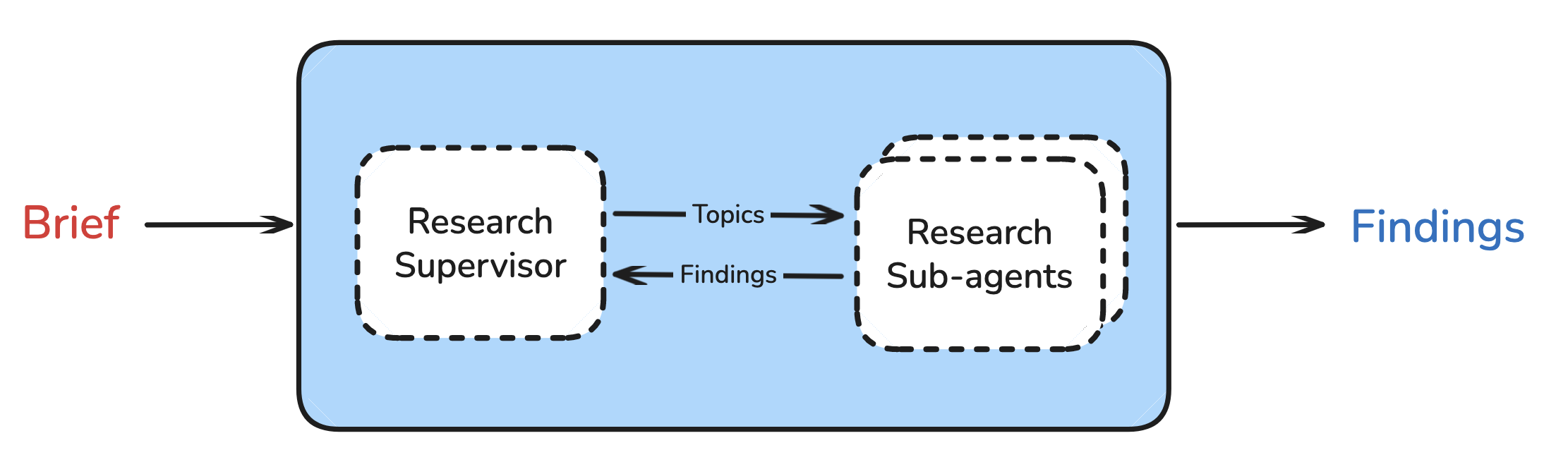
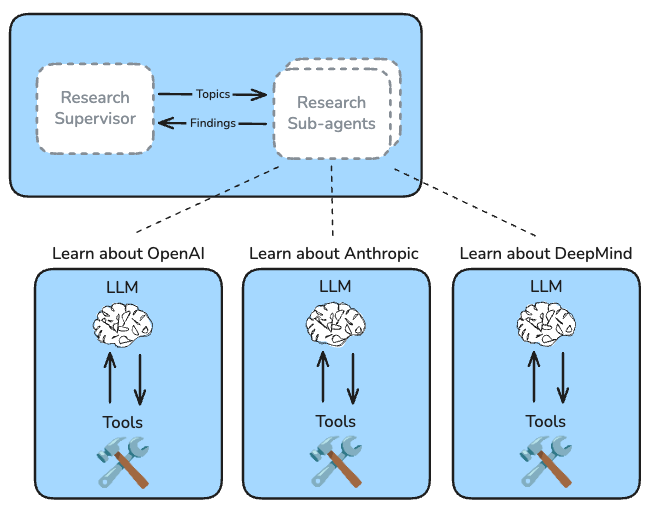
Research Supervisor
The supervisor has a simple job: delegate research tasks to an appropriate number of sub-agents. The supervisor determines if the research brief can be broken-down into independent sub-topics and delegates to sub-agents with isolated context windows. This is useful because it allows the system to parallelize research work, finding more information faster.
Research Sub-Agents
Each research sub-agent is presented with a sub-topic from the supervisor. The sub-agent is prompted to focus only on a specific topic and doesn’t worry about the full scope of research brief – that's a job for the supervisor. Each sub-agent conducts research as a tool-calling loop, making use of search tools and / or MCP tools configured by the user.
When each sub-agent finishes, it makes a final LLM call to write a detailed answer to the subquestion posed, taking into account all of its research and citing helpful sources. This is important because there can be a lot of raw (e.g. scraped web pages) and irrelevant (e.g. failed tool calls, or irrelevant web sites) information collected from tool call feedback.
If we return this raw information to the supervisor, the token usage can bloat significantly and the supervisor is forced parse through more tokens in order to isolate the most useful information. So, our sub-agent cleans up its findings and returns them to the supervisor.
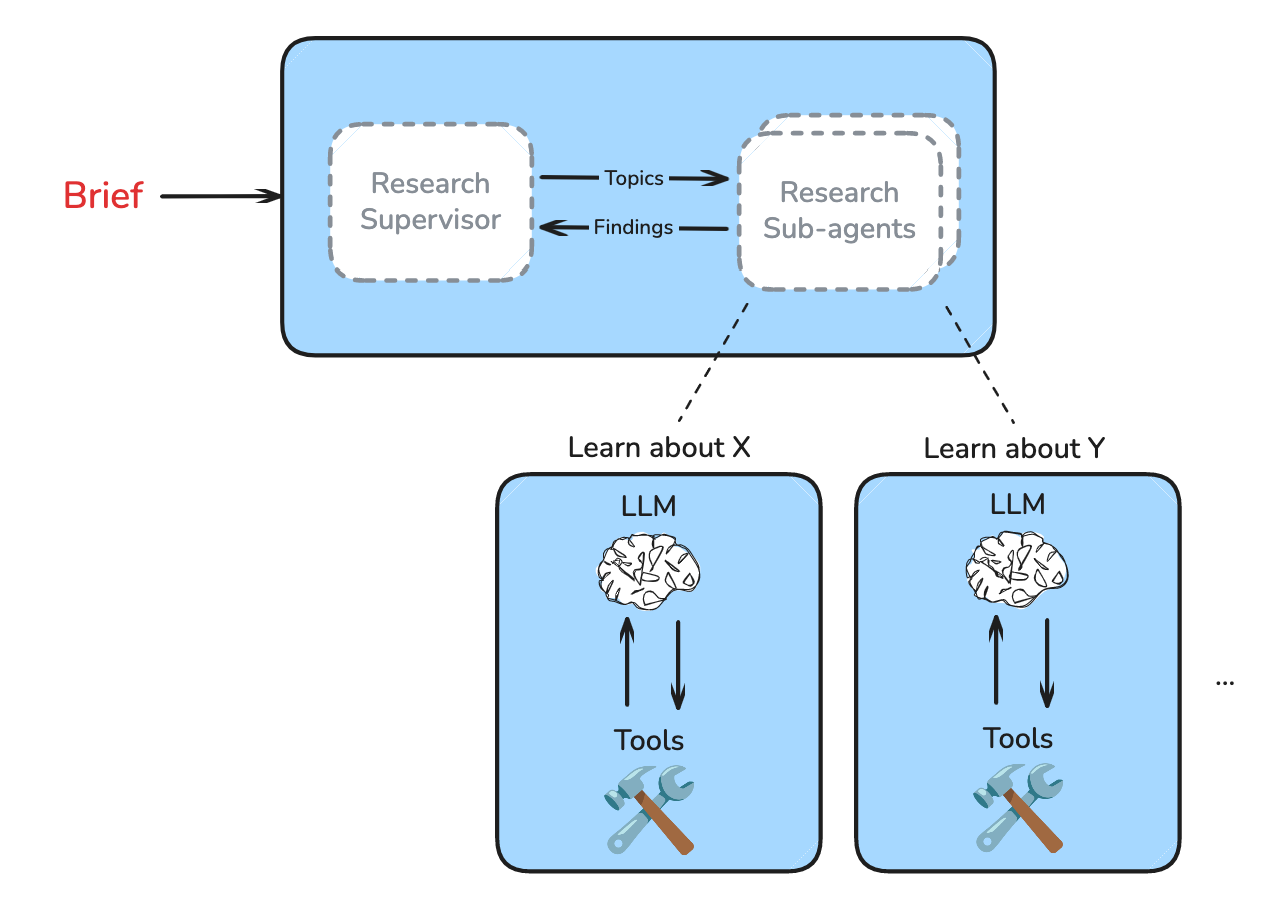
Research Supervisor Iteration
The supervisor reasons about whether the findings from the sub-agents sufficiently address the scope of work in the brief. If the supervisor wants more depth, it can spawn further sub-agents to conduct more research. As the supervisor delegates research and reflects on results, it can flexibly identify what is missing and address these gaps with follow-up research.
Phase 3: Report Writing
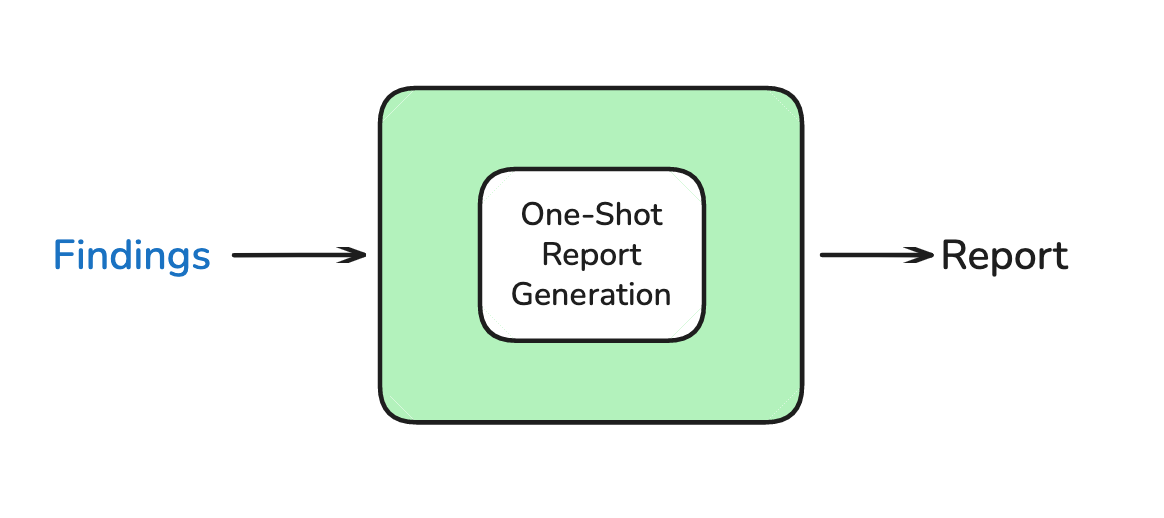
The goal of report writing is to fulfill the request in the research brief using the gathered context from sub-agents. When the supervisor deems that the gathered findings are sufficient to address the request in the research brief, then we move ahead to write the report.
To write the report, we provide an LLM with the research brief and all of the research findings returned by sub-agents. This final LLM call produces an output in one-shot, steered by the brief and answered with the research findings.
Lessons
Only use multi-agent for easily parallelized tasks
Multi vs. single-agent is an important design consideration. Cognition has argued against multi-agent because sub-agents working in parallel can be difficult to coordinate. If the task (e.g., building an application) requires the multi-agent outputs to function together, then coordination is a risk.
We also learned this lesson. Earlier versions of our research agent wrote sections of the final report in parallel with sub-agents. It was fast, but we faced a problem that Cognition raised: the reports were disjoint because the section-writing agents were not well coordinated. We resolved this by using multi-agent for only the research task itself, performing writing after all research was done.
Multi-agent is useful for isolating context across sub-research topics
Our experiments showed that single agent response quality suffers if the request has multiple sub-topics (e.g., compare A to B to C). The intuition here is straightforward: a single context window needs to store and reason about tool feedback across all of the sub-topics. This tool feedback is often token heavy. Numerous failure modes, such as context clash, become prevalent as the context window accumulates tool calls across many different sub-topics.
Let’s look at a concrete example
Compare the approaches of OpenAI vs Anthropic vs Google DeepMind to AI safety. I want to understand their different philosophical frameworks, research priorities, and how they're thinking about the alignment problem.
Our single agent implementation used its search tool to send separate queries about each frontier lab at the same time.
- 'OpenAI philosophical framework for AI safety and alignment'
- 'Anthropic philosophical framework for AI safety and alignment'
- 'Google DeepMind philosophical framework for AI safety and alignment’
The search tool returned results about all three labs in a single lengthy string. Our single agent reasoned about the results for all three frontier labs and called the search tool again, asking independent queries of each.
- 'DeepMind statements on social choice and political philosophy'
- 'Anthropic statements on technical alignment challenges'
- 'OpenAI technical reports on recursive reward modeling'
In each tool-call iteration, the single agent juggled context from three independent threads. This was wasteful from a token and latency perspective. We don’t need tokens about OpenAI’s recursive reward modeling approach to help us generate our next query about DeepMind’s alignment philosophies. Another important observation was that a single agent handling multiple topics would naturally research each topic less deeply (# of search queries) before choosing to finish.
Multi-agent supervisor enables the system to tune to required research depth
Users do not want simple requests to take 10+ minutes. But, there are some requests that require research with higher token utilization and latency, as Anthropic has nicely shown.
The supervisor can handle both cases by selectively spawning sub-agents to tune the level of research depth needed for a request. The supervisor is prompted with heuristics to reason about when research should be parallelized, and when a single thread of research is sufficient. Our deep research agent has the flexibility to choose whether to parallelize research or not.
Context Engineering is important to mitigate token bloat and steer behavior
Research is a token-heavy task. Anthropic reported that their multi-agent system used 15x more tokens than a typical chat application! We used context engineering to mitigate this.
We compress the chat history into a research brief, which prevents token-bloat from prior messages. Sub-agents prune their research findings to remove irrelevant tokens and information before returning to the supervisor.
Without sufficient context engineering, our agent was prone to running into context window limits from long, raw tool-call results. Practically, it also helps save $ on token spend and helps avoid TPM model rate limits.
Next Steps
Open deep research is a living project and we have several ideas we want to try. These are some of the open questions that we’re thinking about.
- What is the best way to handle token-heavy tool responses, and what is the best way to filter out irrelevant context to reduce unnecessary token expenditure?
- Are there any evaluations worth running in the hot path of the agent to ensure high quality responses?
- Deep research reports are valuable and relatively expensive to create, can we store this work and leverage these in the future with long-term memory?
Using Open Deep Research
LangSmith Studio
You can clone our LangGraph code and run Open Deep Research locally with LangSmith Studio. You can use Studio to test out the prompts and architecture and tailor them more specifically to your use cases!
LangChain Academy
Check out our course on how to build your own deep research agent to handle research tasks.