

Evaluations are a key technique for improving your application — whether you’re working on a single prompt or a complex agent. As you compare models, update logic, or iterate on your architecture, evaluations are a reliable way to score outputs and understand the impact of your changes.
But, one big challenge we hear consistently from teams is: "Our evaluation scores don't match what we'd expect a human on our team to say." This mismatch leads to noisy comparisons, and time wasted chasing false signals.
That’s why we’re introducing Align Evals, a new feature in LangSmith that helps you calibrate your evaluators to better match human preferences. This feature was inspired by Eugene Yan's article on building LLM-as-a-judge evaluators.
This feature is available today for all LangSmith Cloud users and will be released to LangSmith Self-Hosted later this week. View our video walkthrough or read our developer docs to get started.
Creating high quality LLM-as-a-judge evaluators just got easier
Until now, iterating on evaluators has often involved a lot of guesswork. It's hard to spot trends or inconsistencies in evaluator behavior and, after making changes to your evaluator prompt, it can be unclear which data points caused scores to shift or why.
With this new LLM-as-a-Judge Alignment feature, you get:
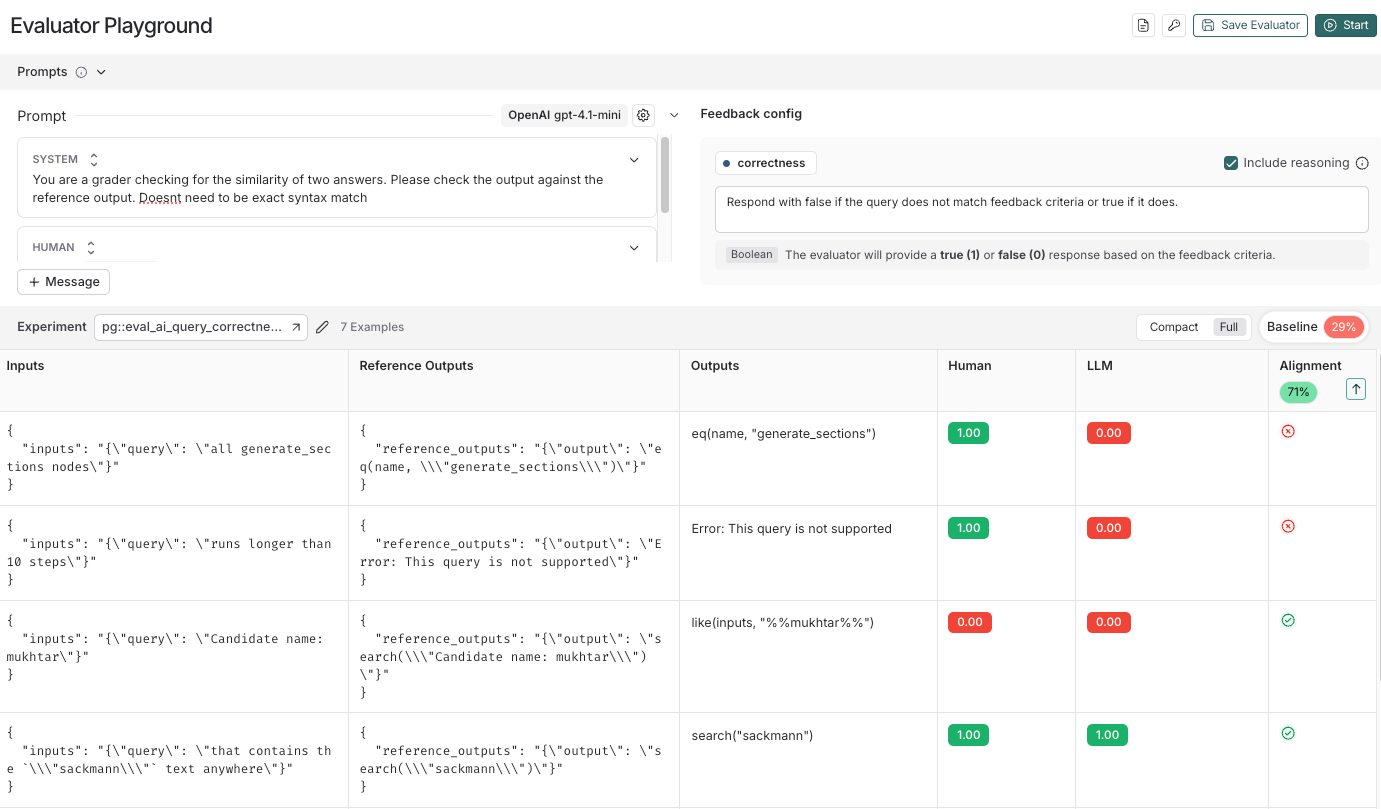
- A playground-like interface to iterate on your evaluator prompt and see the evaluator’s “alignment score”
- Side-by-side comparison of human-graded data and LLM-generated scores, with sorting to identify “unaligned” cases
- A saved baseline alignment score in order to compare your latest changes to the previous version of your prompt
How it works
Here’s how the alignment flow works:
1. Select evaluation criteria
The first step is identifying the right evaluation criteria. Your eval criteria should include the things your app should do well. For example, if you’re building a chat app, correctness is important —but so is conciseness. A technically accurate answer that takes many paragraphs to get to the point will still frustrate users.
2. Select data for human review
Create a set of representative examples from your app. These should cover both good and bad examples —the goal is to cover the range of outputs that your app would actually generate. For example, if you’re working on adding a new product that your customer support assistant can answer questions about, include both correct responses and incorrect ones.
3. Grade the data with expected scores
For each eval criteria, manually assign a score for each example. These scores become your “golden set” which will serve as a benchmark against which the evaluator’s responses will be judged.
4. Create an evaluator prompt and test it against the human grading
Create an initial prompt for your LLM evaluator and use the the alignment results to iterate. For each version of your prompt, you'll test it against your human-graded examples to see how well your LLM's scores align with yours.
For example, if your LLM consistently over-scores certain responses, try adding clearer negative criteria. Improving your evaluator score is meant to be an iterative process. Learn more about best practices on iterating on your prompt in our docs.
Whats next?
We’re just getting started. This is the first step towards helping you build better evaluators. Looking ahead, you can expect:
- Analytics so you can track how your evaluator’s performance evolves over time.
- Automatic prompt optimization, where we automatically generate prompt variations for you!
Give it a try! Get started by heading to our developer documentation or watch our video tutorial. Let us know what you think by providing feedback in the LangChain Community fourm.