TLDR: Our coding agent went from Top 30 to Top 5 on Terminal Bench 2.0. We only changed the harness. Here’s our approach to harness engineering (teaser: self-verification & tracing help a lot).
The Goal of Harness Engineering
The goal of a harness is to mold the inherently spiky intelligence of a model for tasks we care about. Harness Engineering is about systems, you’re building tooling around the model to optimize goals like task performance, token efficiency, latency, etc. Design decisions include the system prompt, tool choice, and execution flow.
But how should you change the harness to improve your agent?
At LangChain, we use Traces to understand agent failure modes at scale. Models today are largely black-boxes, their inner mechanisms are hard to interpret. But we can see their inputs and outputs in text space which we then use in our improvement loops.
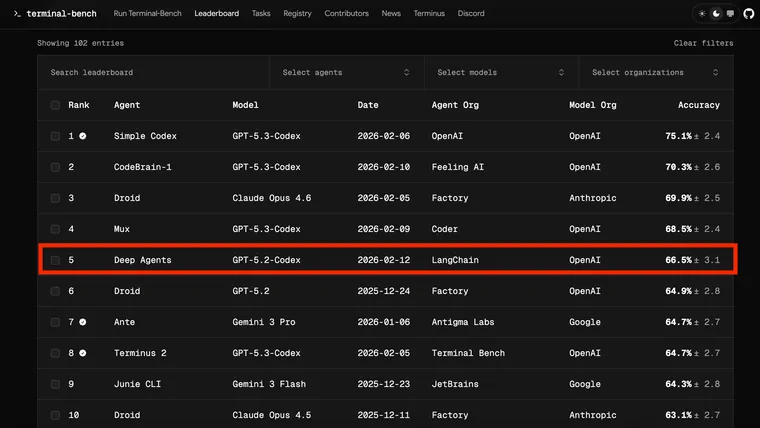
We used a simple recipe to iteratively improve deepagents-cli (our coding agent) 13.7 points from 52.8 to 66.5 on Terminal Bench 2.0. We only tweaked the harness and kept the model fixed, gpt-5.2-codex.
Experiment Setup & The Knobs on a Harness
We used Terminal Bench 2.0, a now standard benchmark to evaluate agentic coding. It has 89 tasks across domains like machine learning, debugging, and biology. We use Harbor to orchestrate the runs. It spins up sandboxes (Daytona), interacts with our agent loop, and runs verification + scoring.
Every agent action is stored in LangSmith. It also includes metrics like latency, token counts, and costs.
The Knobs we can Turn
An agent harness has a lot of knobs: system prompts, tools, hooks/middleware, skills, sub-agent delegation, memory systems, and more. We deliberately compress the optimization space and focus on three: System Prompt, Tools, and Middleware (our term for hooks around model and tool calls).
We start with a default prompt and standard tools+middleware. This scores 52.8% with GPT-5.2-Codex. A solid score, just outside the Top 30 of the leaderboard today, but room to grow.

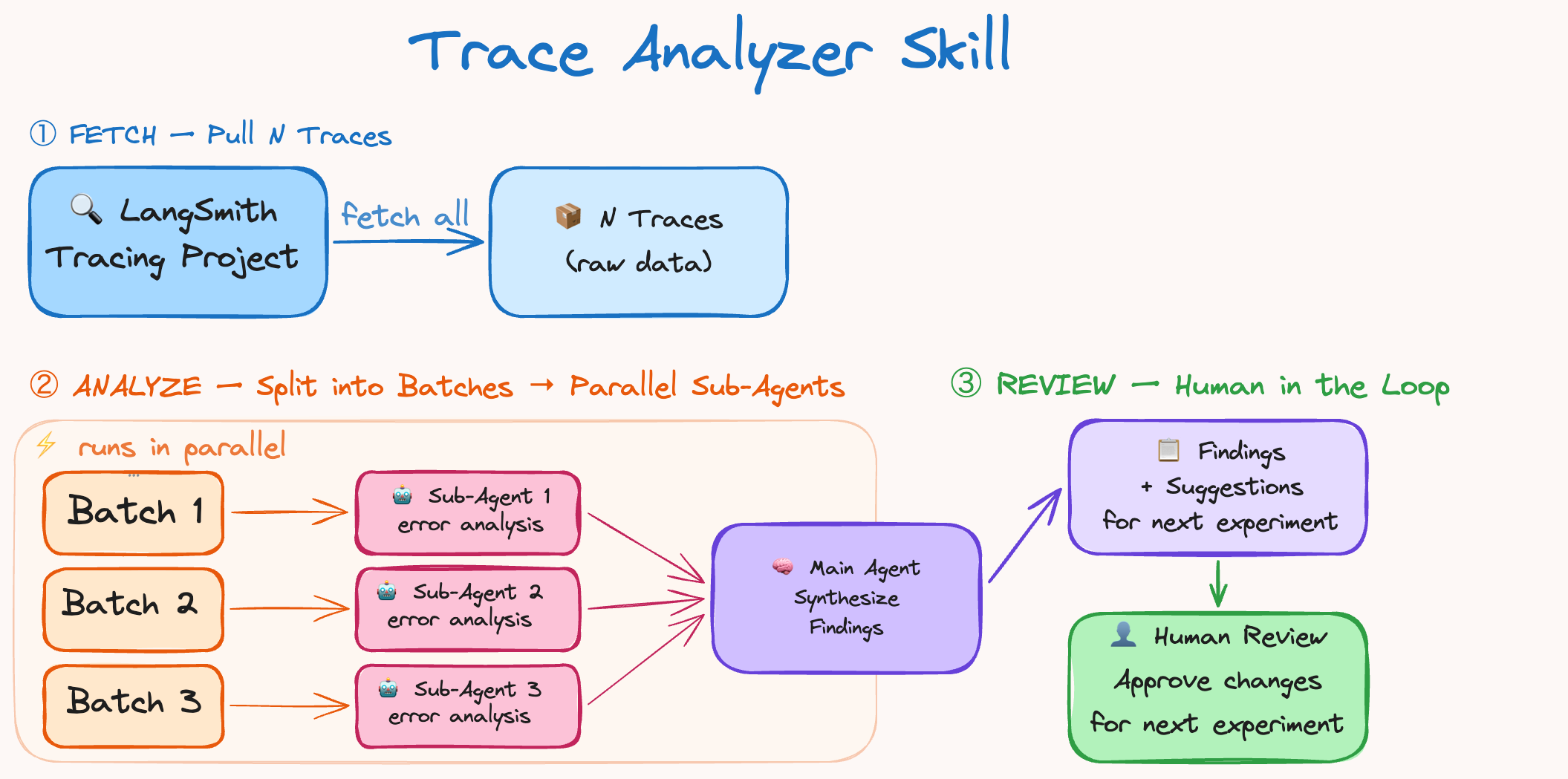
The Trace Analyzer Skill
We wanted trace analysis to be repeatable so we made it into an Agent Skill. This serves as our recipe to analyze errors across runs and make improvements to the harness. The flow is:
- Fetch experiment traces from LangSmith
- Spawn parallel error analysis agents → main agent synthesizes findings + suggestions
- Aggregate feedback and make targeted changes to the harness.
This works similarly to boosting which focuses on mistakes from previous runs. A human can be pretty helpful in Step 3 (though not required) to verify and discuss proposed changes. Changes that overfit to a task are bad for generalization and can lead to regressions in other Tasks.
Automated trace analysis saves hours of time and made it easy to quickly try experiments. We’ll be publishing this skill soon, we’re currently testing it for prompt optimization generally.
What Actually Improved Agent Performance
Automated Trace analysis allowed us to debug where agents were going wrong. Issues included reasoning errors, not following task instructions, missing testing and verification, running out of time, etc. We go into these improvements in more details in the sections below.
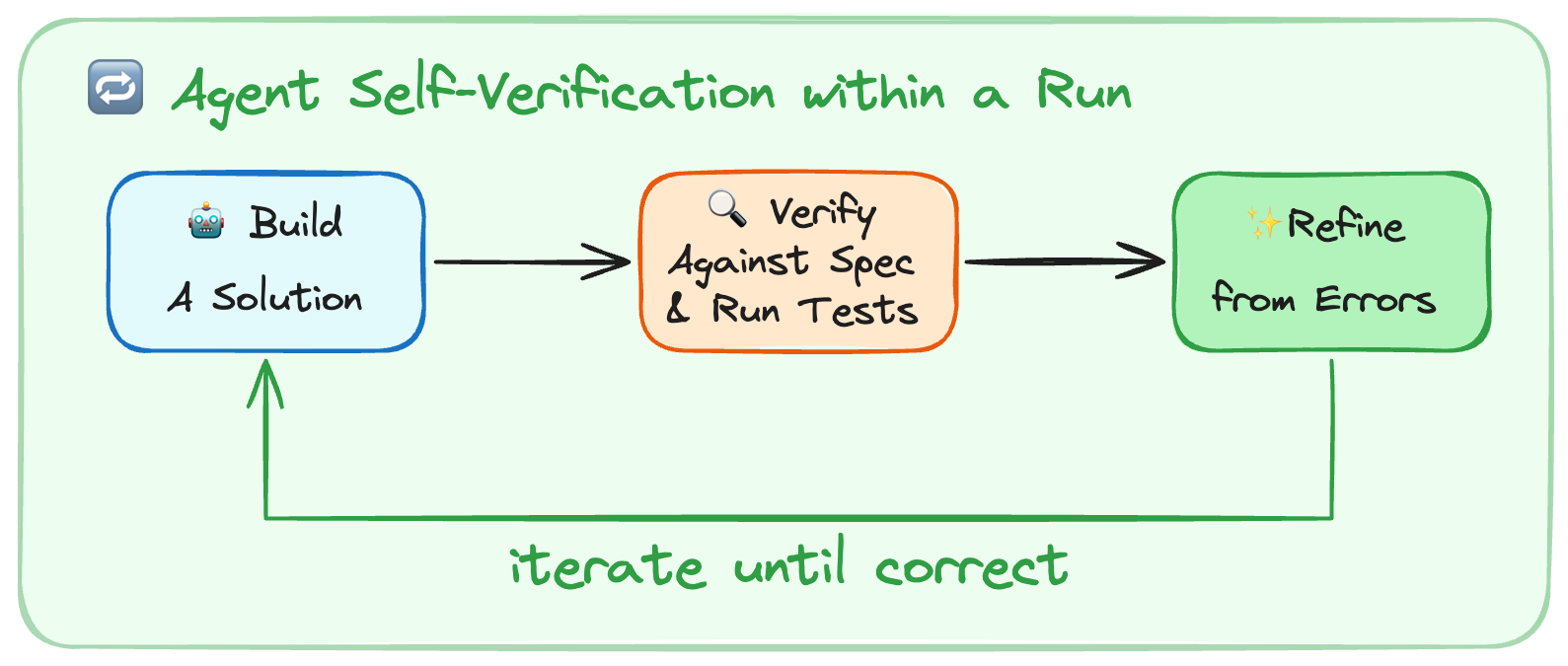
Build & Self-Verify
Today’s models are exceptional self-improvement machines.
Self-verification allows agents to self-improve via feedback within a run. However, they don’t have a natural tendency to enter this build-verify loop.
The most common failure pattern was that the agent wrote a solution, re-read its own code, confirmed it looks ok, and stopped. Testing is a key part of autonomous agentic coding. It helps test for overall correctness and simultaneously gives agents signal to hill-climb against.
We added guidance to the system prompt on how to approach problem solving.
- Planning & Discovery: Read the task, scan the codebase, and build an initial plan based on the task specification and how to verify the solution.
- Build: Implement the plan with verification in mind. Build tests, if they don’t exist and test both happy paths and edge cases.
- Verify: Run tests, read the full output, compare against what was asked (not against your own code).
- Fix: Analyze any errors, revisit the original spec, and fix issues.
We really focus on testing because it powers the changes in every iteration. We found that alongside prompting, deterministic context injection helps agents verify their work. We use a PreCompletionChecklistMiddleware that intercepts the agent before it exits and reminds it to run a verification pass against the Task spec. This is similar to a Ralph Wiggum Loop where a hook forces the agent to continue executing on exit, we use this for verification.
Giving Agents Context about their Environment
Part of harness engineering is building a good delivery mechanism for context engineering. Terminal Bench tasks come with directory structures, built-in tooling, and strict timeouts.
- Directory Context & Tooling: A
LocalContextMiddlewareruns on agent start to map thecwdand other parent+children directories. We runbashcommands to find tools likePythoninstallations. Context discovery and search are error prone, so injecting context reduces this error surface and helps onboard the agent into its environment. - Teaching Agents to Write Testable Code: Agents don’t know how their code needs to be testable. We add prompting say their work will be measured against programatic tests, similar to when committing code. For example, Task specs that mention file paths should be followed exactly so the solutions works in an automated scoring step. Prompting that stresses edge-cases helps the agent avoid only checking “happy path” cases. Forcing models to conform to testing standards is a powerful strategy to avoid “slop buildup” over time.
- Time Budgeting: We inject time budget warnings to nudge the agent to finish work and shift to verification. Agents are famously bad at time estimation so this heuristic helps in this environment. Real world coding usually doesn’t have strict time limits, but without adding any knowledge of constraints, agents won’t work within time bounds.
The more that agents know about their environment, constraints, and evaluation criteria, the better they can autonomously self-direct their work.
The purpose of the harness engineer: prepare and deliver context so agents can autonomously complete work.
Encouraging Agents to Step Back & Reconsider Plans
Agents can be myopic once they’ve decided on a plan which results in “doom loops” that make small variations to the same broken approach (10+ times in some traces).
We use a LoopDetectionMiddleware that tracks per-file edit counts via tool call hooks. It adds context like “…consider reconsidering your approach” after N edits to the same file. This can help agents recover from doom loops, though the model can continue down the same path if it thinks it’s correct.
Important note. This is a design heuristic that engineers around today’s perceived model issues. As models improve, these guardrails will likely be unnecessary, but today helps agents execute correctly and autonomously.
Choosing How Much Compute to Spend on Reasoning
Reasoning models can run autonomously for hours so we have to decide how much compute to spend on every subtask. You can use the max reasoning budget on every task, but most work can benefit from optimizing reasoning compute spend.
Terminal Bench timeout limits create a tradeoff. More reasoning helps agents evaluate each step, but can burn over 2x more tokens/time. gpt-5.2-codex has 4 reasoning modes, low, medium, high, and xhigh.
We found that reasoning helps with planning to fully understand the problem, some Terminal Bench tasks are very difficult. A good plan helps get to a working solution more quickly.
Later stage verification also benefits from more reasoning to catch mistakes and get a solution submitted. As a heuristic, we choose a xhigh-high-xhigh "reasoning sandwich" as a baseline.
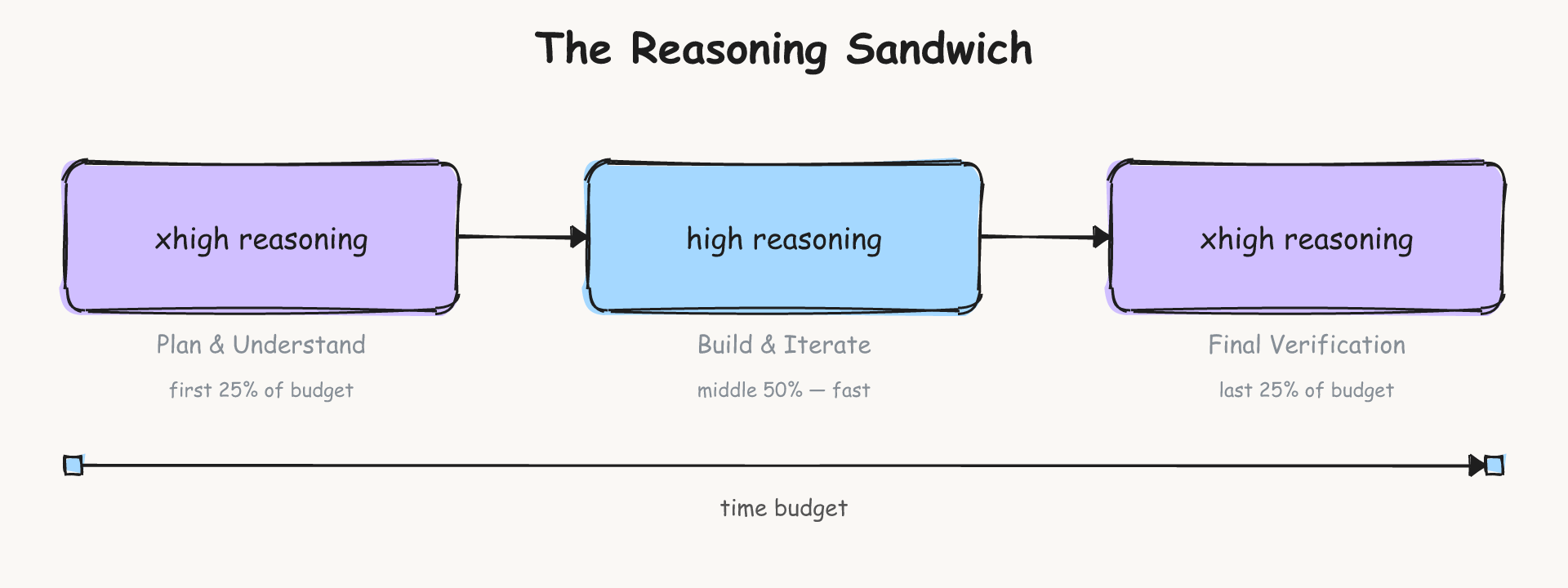
Running only at xhigh scored poorly at 53.9% due to agent timeouts compared to 63.6% at high. There weren’t large differences in trial runs across reasoning budget splits so we stuck with our approach which pushed the score to 66.5%.
The natural approach for models is Adaptive Reasoning, seen with Claude and Gemini models where the model decides how much compute to spend on reasoning.
In a multi-model harness, balancing reasoning budgets could play out as using a large model for planning and handing off to a smaller model for implementation.
Practical Takeaways for Building Agent Harnesses
The design space of agents is big. Here are some general principles from our experiments and building deepagents overall.
- Context Engineering on Behalf of Agents. Context assembly is still difficult for agents today, especially in unseen environments. Onboarding models with context like directory structures, available tools, coding best practices, and problem solving strategies helps reduce the error surface for poor search and avoidable errors in planning.
- Help agents self-verify their work. Models are biased towards their first plausible solution. Prompt them aggressively to verify their work by running tests and refining solutions. This is especially important in autonomous coding systems that don’t have humans in the loop.
- Tracing as a feedback signal. Traces allow agents to self-evaluate and debug themselves. It’s important to debug tooling and reasoning together (ex: models go down wrong paths because they lack a tool or instructions how to do something).
- Detect and fix bad patterns in the short term. Models today aren’t perfect. The job of the harness designer is to design around today’s shortcomings while planning for smarter models in the future. Blind retries and not verifying work are good examples. These guardrails will almost surely dissolve over time, but to build robust agent applications today, they’re useful tools to experiment with.
- Tailor Harnesses to Models. The Codex and Claude prompting guides show that models require different prompting. A test run with Claude Opus 4.6 scored
59.6%with an earlier harness version, competitive but worse than Codex because we didn’t run the same Improvement Loop with Claude. Many principles generalize like good context preparation and a focus on verification, but running a few rounds of harness iterations for your task helps maximize agent performance across tasks.
There’s more open research to do in harness design. Interesting avenues include multi-model systems (Codex, Gemini, and Claude together), memory primitives for continual learning so agents can autonomously improve on tasks, and measuring harness changes across models.
For the outer loop of improving agents, we’re looking at methods like RLMs to more efficiently mine traces. We’ll be continuing work to improve the harness and openly share our research.
We created a dataset of our Traces to share with the community.
Deep Agents is open source. Python and Javascript.
To more hill climbing and open research.