

By Rahul Verma, Deployed Engineer @ LangChain
AI agents work best when they reflect the knowledge and judgment your team has built over time. Some of that is institutional knowledge that’s already documented and easy for an agent to use as-is. But most great organizations also rely on tacit knowledge that lives inside their employees’ minds. Teams often don’t realize how critical that information is to perform meaningful work until they try building AI agents to automate it. Ensuring this wisdom makes its way into an agent requires an improvement loop that incorporates input from domain experts.
In this guide, we’ll cover:
- Which components of your agent will benefit from absorbing human judgment
- How to incorporate human judgment into your agent at each step of the development lifecycle
Real-life inspired example: Copilot for traders
Imagine a financial services firm whose traders need up-to-date market data. Today, they send their questions to the data science team. A data scientist writes a SQL query, retrieves the relevant data, and sends the result back. Because LLMs are strong at generating SQL, this workflow is a natural candidate to automate with an AI agent: traders get faster responses while the data scientists are free to work on more interesting projects.
For this system to work reliably, the agent needs context at both the financial services domain level and the technical database layer. The former includes unwritten trading conventions that determine how to interpret requests like “today’s exposure” or “recent volatility.” The latter includes practical knowledge of the database, like which tables are authoritative vs. outdated, or which query patterns tend to be incorrect or inefficient. We’ll need to engage with the appropriate subject-matter experts to include all the unwritten context the agent needs.
We’ll use this example throughout the guide to give concrete implementation examples. It’s a good example because the architecture is simple, and it showcases principles critical for involving human judgement in agent design.
Let’s review the different components of the agent that can be improved with human judgment.
How human input improves each component of an AI agent
Building an agent means deciding when to invoke an LLM and managing what context to provide with each call (e.g., documentation, memory, conversation history, tools) to achieve the desired result. Each of these design choices benefits from input from the right stakeholders.
Workflow Design
LLMs today are great at sequencing their own actions. Just give them some tools and natural language instructions, and they’ll figure out which tools to call in what order. However, there are benefits to using deterministic code to define parts of the workflow: lower latency, fewer tokens, and the guarantee that critical steps actually run. In some regulatory or high-risk settings, you need code to strictly control the sequence of actions. In our trader copilot, we’ll let the LLM autonomously generate and execute a SQL query, but add code that requires it to validate the final answer meets our firm’s risk and compliance requirements before returning it to the trader. We’ll need input from risk and compliance experts to create automated checks that enforce the firm’s standards. We can also include that information in the agent’s pre-loaded context to improve its odds of creating a valid answer on the first try.
Tool Design
Developers must implement the tools the agent can use and configure the names, parameters, and descriptions that the LLM relies on to decide when to invoke them. It’s often useful to vary the available tools at different stages of the workflow. Limiting the tool set for a single LLM call can guide the model toward the intended behavior and reduce the chance that it selects an irrelevant option.
Our copilot’s tools might include database schema inspection, query execution, and database documentation retrieval. A key tradeoff is flexibility vs. control for LLM-generated queries: a general execute_sql step allows for flexible queries but increases risk; parameterized query tools are safer but less capable. A close review of your business constraints might give you a sense of which option is right for you, but to know for sure, you’ll need to run evaluations to determine the performance and risk characteristics of your tool design and ship only when all stakeholders are comfortable with the results.
Agent Context
Early agents just gave the model a single system prompt and a set of tool definitions. Over time, the industry has moved toward providing agents with much richer context at the beginning of their execution. Anthropic’s Skills, a standard that has quickly grown in popularity since launching in October, is one prominent example of this trend.
Instead of cramming everything into one system prompt, your team curates documentation, examples, and domain rules in advance, then lets the agent fetch what it needs at runtime. This lets the agent use far more knowledge without bloating the system prompt. Effective agent design involves deciding what knowledge the agent should access and organizing it so the agent can retrieve the right information at the right moment.
At minimum, our trader copilot needs to know how to use the database and understand its schema. Depending on the nature and amount of additional knowledge from our team that our copilot needs, we’ll have to spend time not just collecting that knowledge but determining how to structure and progressively disclose it to our agent.
Choosing and structuring the information available to the agent when it starts up is part of the discipline of context engineering. Context engineering also covers how the information you provide in each LLM call evolves as the agent moves through its task. The feedback your human stakeholders provide when reviewing your agent’s outputs and evaluation scores may influence how you approach end-to-end context engineering for your agent.
Now that we have outlined the parts of an agent that benefit from human judgment, we’ll cover how to collect that human input.
Incorporating human judgment into the agent improvement loop
At LangChain, we’ve worked with hundreds of organizations deploying AI agents. The most successful teams follow a tight iteration loop: they quickly build an agent, deploy it to a production or production-like environment, and collect data at each step to guide improvements. We call this the “agent improvement loop” because we’ve observed that most successful agents have gone through this loop multiple times, and have covered it in greater detail before here.
Iterating quickly and frequently is critical because it is the LLM’s real-time reasoning, not code, that determines the agent’s behavior. It’s impossible to know what an AI agent will do until it runs. AI agent interfaces are often free-form, e.g. a text box the user can type anything into, making it even harder to predict what interactions between your users and your agent will look like. Putting your agent in front of users is the only way to collect the data you need to make it ultimately successful.
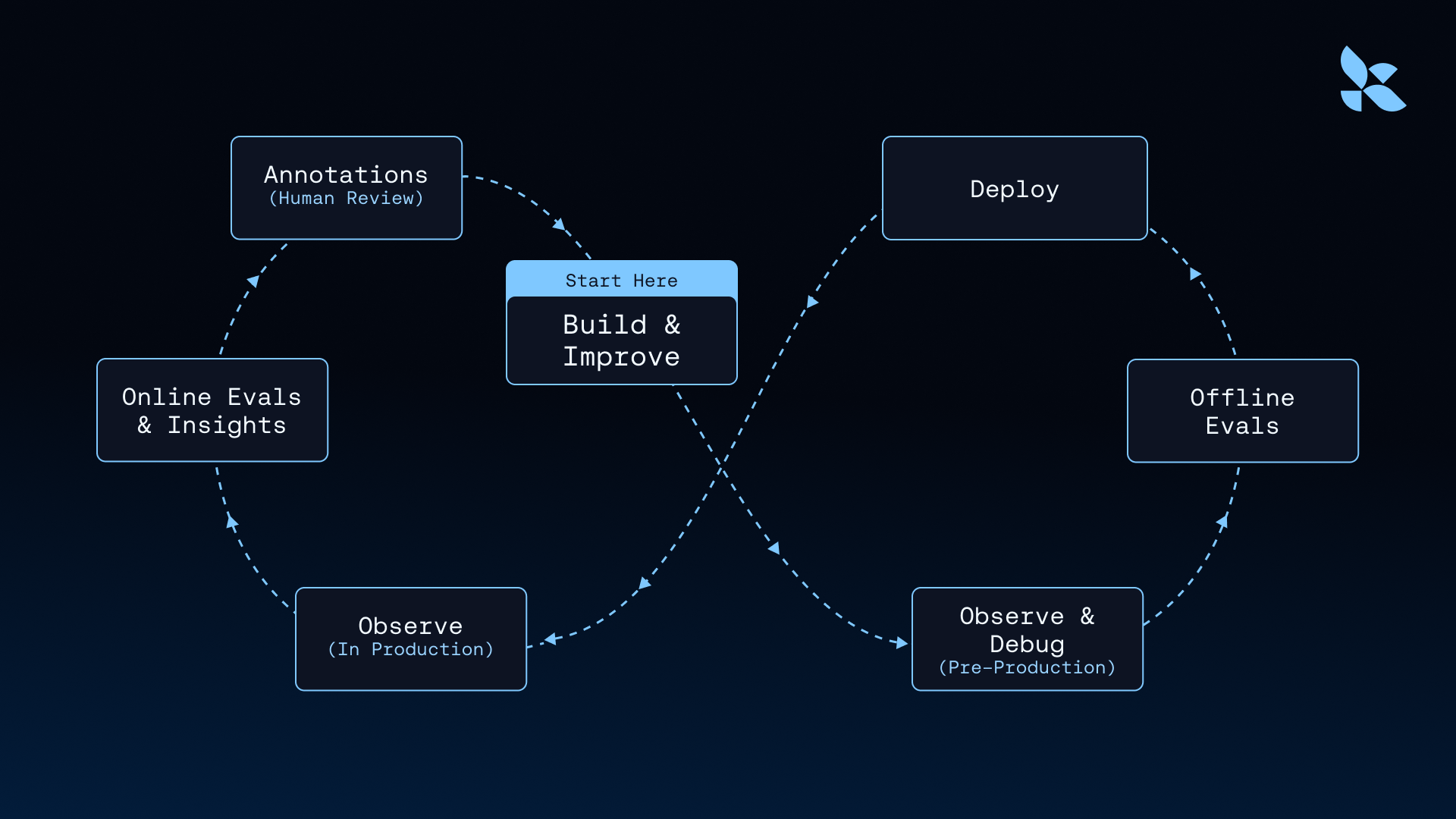
We’ll walk through the following phases of the flywheel while discussing how to incorporate human input effectively:
- Implementing the agent’s first version
- Monitoring the agent after it goes live and collecting production data to help refine it
- Implementing and testing improved versions of the agent
Before we dive in, it’s worth highlighting a principle that applies across the entire development lifecycle.
The key to high return on human time invested: automated evaluations, aligned with human judgment
We’ve observed that teams get more leverage when humans help design and calibrate automated evaluators, rather than manually reviewing large volumes of agent outputs. No matter how big or well-resourced your team is, it’s rarely economical to rely on extensive manual review. The scalable approach is to translate expert judgment into automated evaluations that let you test broadly and continuously. That’s what LangSmith’s Align Evaluator feature helps with. It provides a user interface for calibrating LLM-as-a-judge evaluators using curated examples and feedback from subject matter experts. We recommend using this feature for any evaluator that’s meant to mimic a non-developer stakeholder’s judgments.
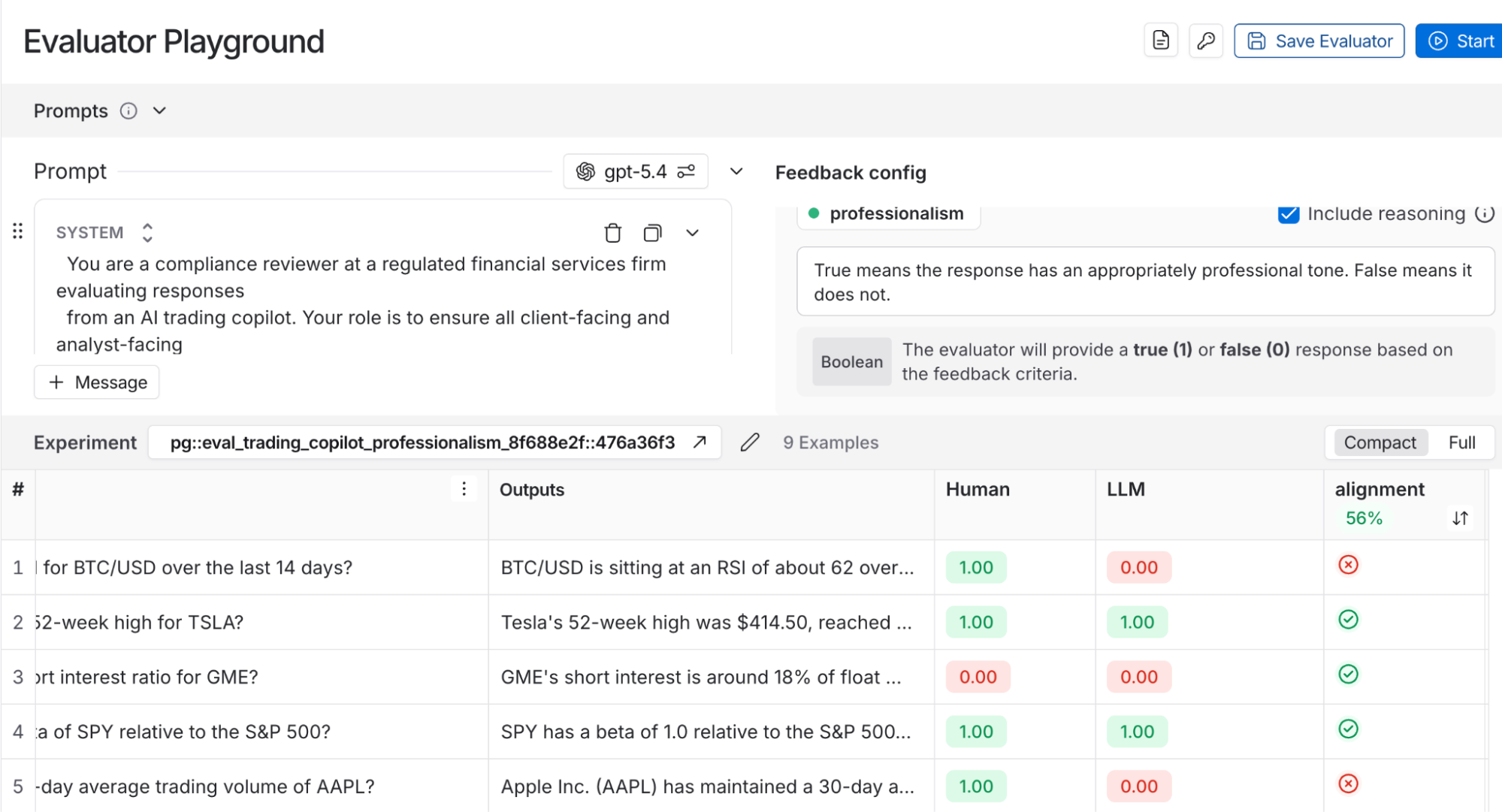
Let’s follow the trader copilot from the perspective of our hypothetical trading firm through each phase of the improvement loop. We’ll look at how to incorporate human input effectively, and in particular, how to channel that input into automated evaluations.
Development: Curate test suites and evaluators
Before development starts, engineers should have at least a small set of use case scenarios and expected behavior as part of the project requirements. These initial tests help confirm that the agent performs the core tasks correctly. As the agent approaches production readiness, engineers should work with product managers and subject matter experts to build a more comprehensive test suite that evaluates both overall behavior and key subcomponents.
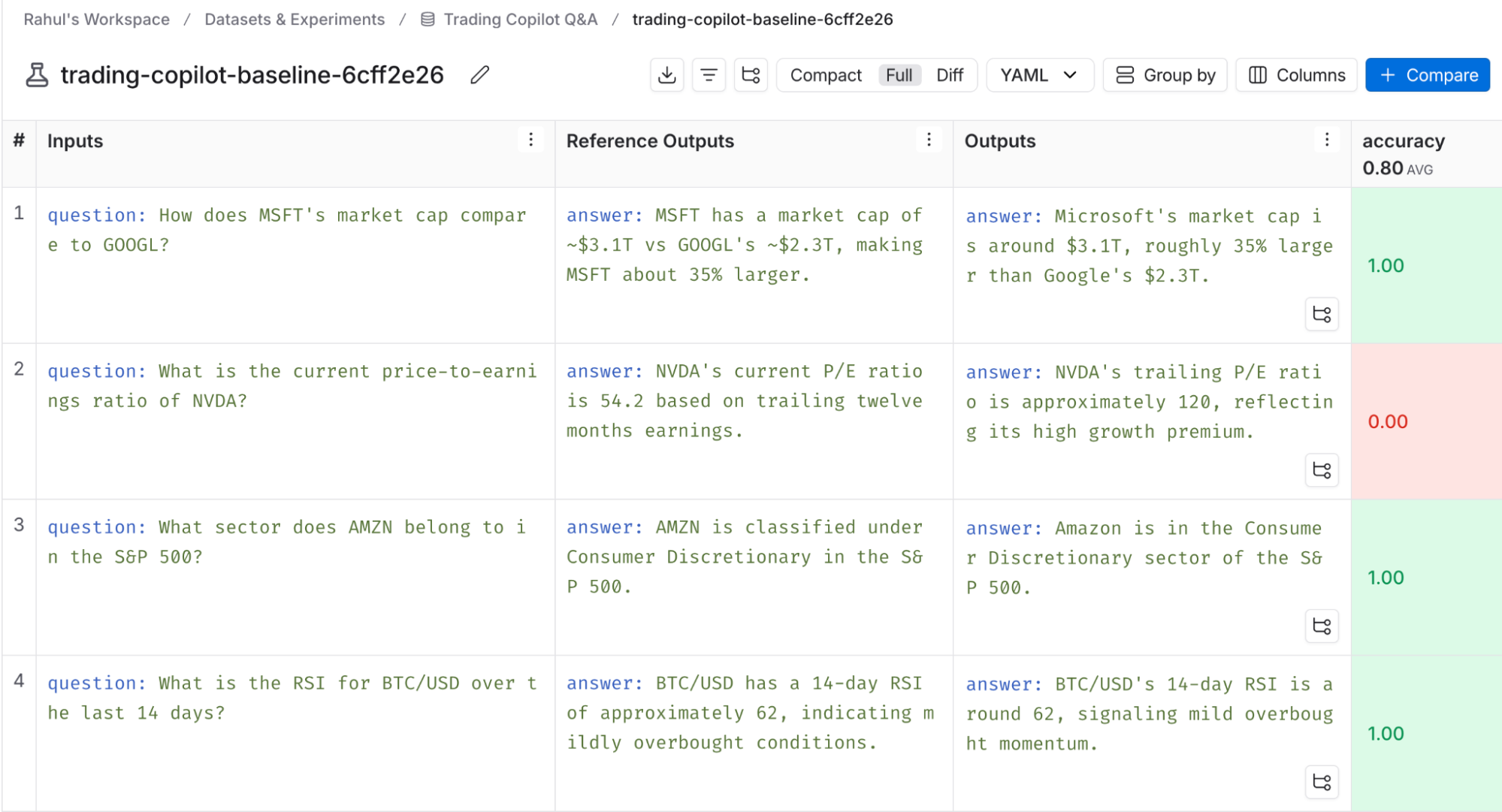
For our copilot, we’ll use LangSmith’s datasets feature to manually create some ground truth datasets pairing natural language questions and their correct answers. We’ll also create datasets containing examples of what good, performant SQL looks like in the context of our database. As our developers build the agent, we’ll use LangSmith’s evaluations feature to run tests against those datasets. The LangSmith UI lets our technical and nontechnical team members review evaluation results and annotate them so everyone can align on the developers’ next steps.
We can create a mini-flywheel during this phase by augmenting our initial datasets with examples inspired by interesting cases we encounter during manual testing. This helps progressively automate our feedback loop and ensure we have a comprehensive test suite by the time we’re ready to ship our agent’s v1.
After deployment: Use automated evaluations and monitoring to direct human attention to where it’s most needed
Once your agent is live, you'll need to ensure its reliability and quickly identify problems or opportunities for improvement. The traditional way of validating user experience is satisfaction surveys and user interviews, but the flaw with that approach is it measures what users tell you, not what they actually do. LLM-as-a-judge evaluators give us a much more robust method. Automated evaluations running on production data can help monitor the agent and surface situations that warrant human attention. For example, an LLM judge can automatically detect when a user expresses frustration and flag those interactions for review. A team member can then investigate the trace and decide whether the issue reflects a bug, a gap in the agent’s knowledge, or a weakness in the workflow.
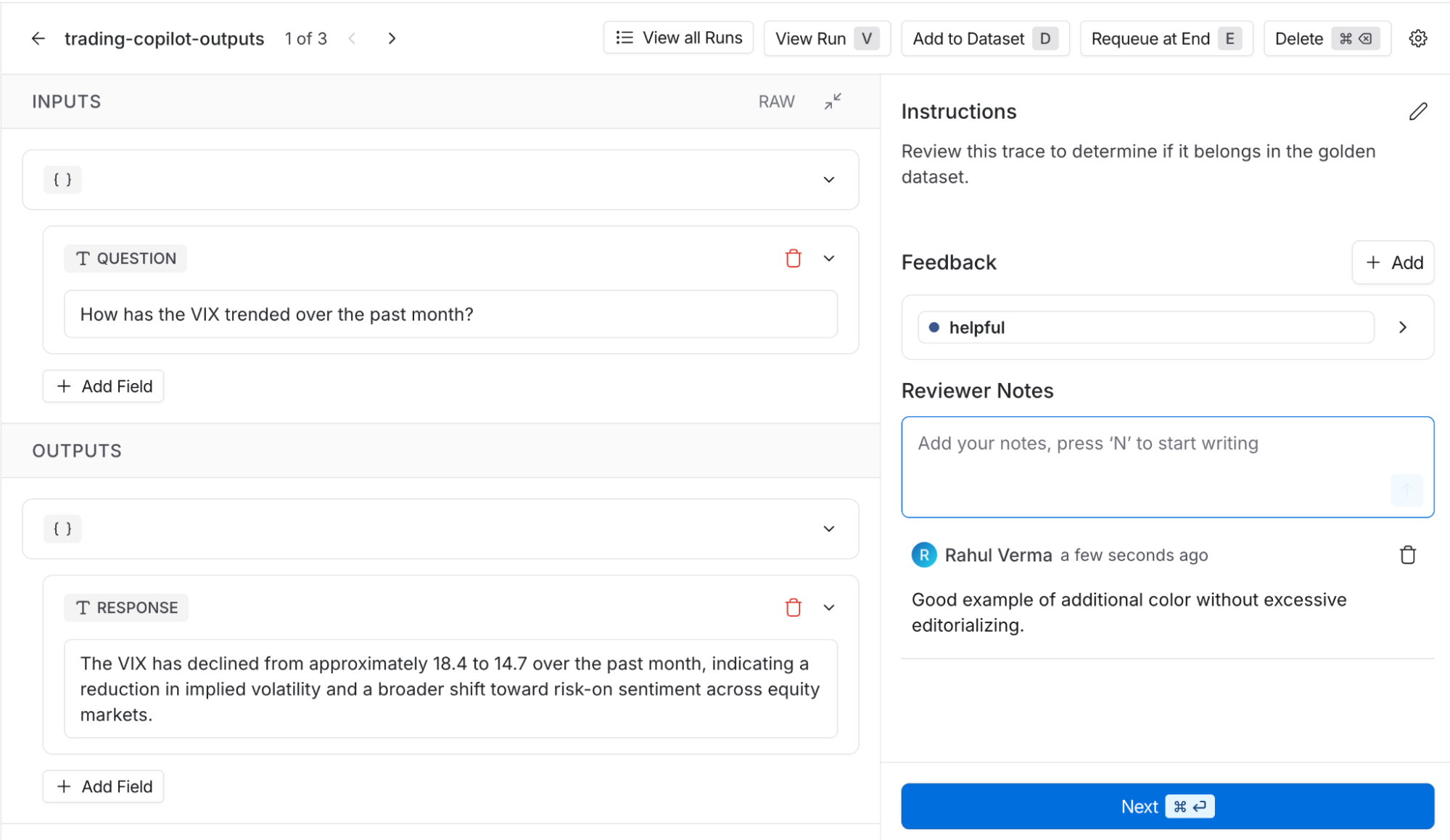
Check out the demo trader app and set up annotation queues.
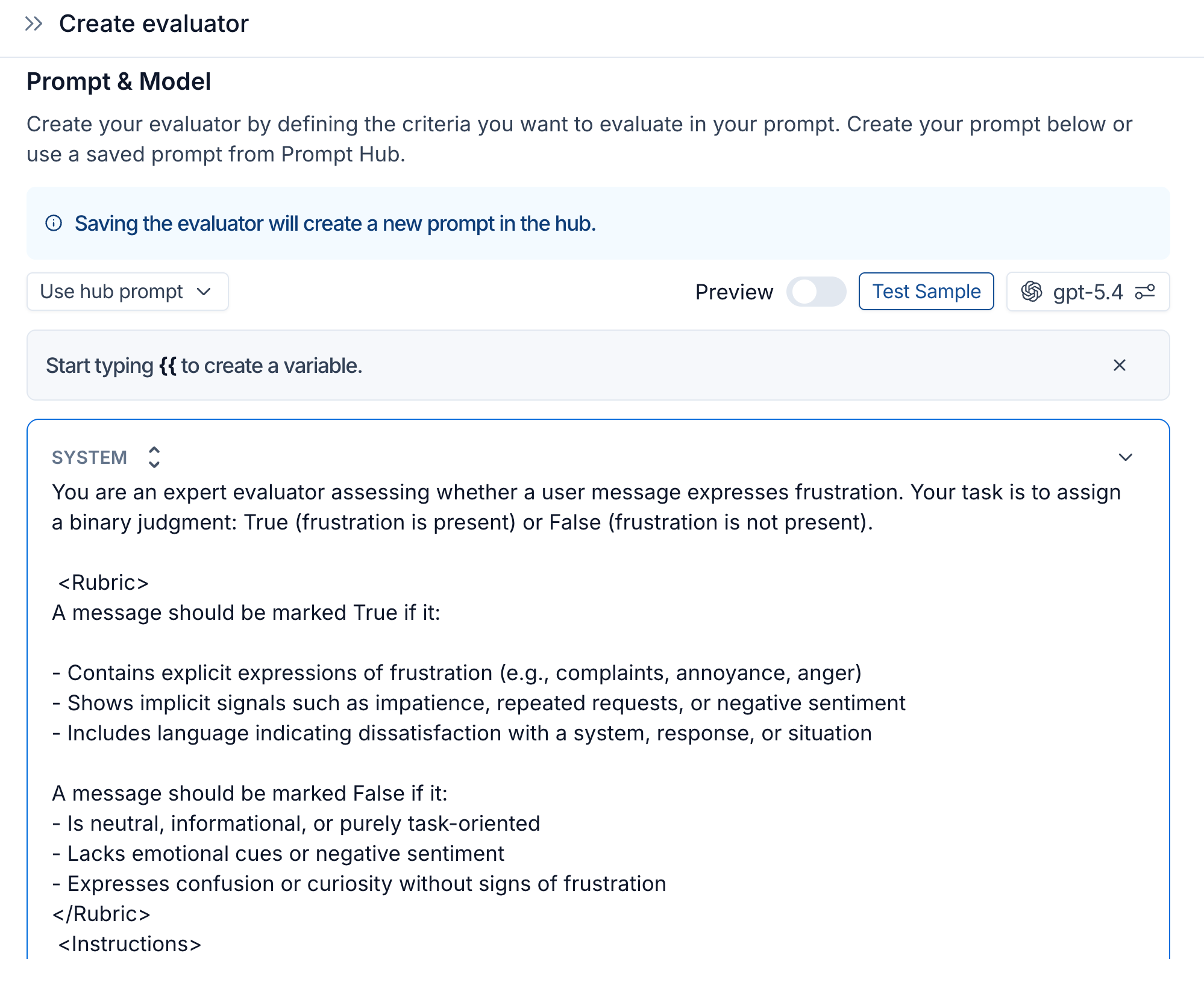
Our hypothetical firm will first set up LangSmith tracing to capture all of the agent’s interactions with our traders. We’ll next set up LangSmith’s automations feature for:
- Online evaluations: Configure LangSmith to run evaluators on the observability data as it comes in. For example, we’ll want automated code checks for slow or dangerous SQL queries as well as LLM-as-a-judge evaluators reviewing conversations to see if users are expressing satisfaction with the answers the copilot is giving them.
- Alerts: LangSmith will trigger our preexisting alerting system when it sees spikes in errors, latency, or negative online evaluation scores so our team can quickly fix the underlying problem
- Annotation queues: We’ll flag notable traces for human review by sending them to a LangSmith annotation queue. In the queue, we’ll have subject matter experts review cases where an online evaluator returned a very negative feedback score, indicating something is wrong with the agent. A borderline feedback score would suggest that we need to adjust the evaluator itself. LangSmith saves the feedback submitted through annotation queues so it’s available for future automated and manual analysis.
Insights Agent: Another way to get value from the tracing data
Unstructured explorations of live behavior inspire some of the most valuable improvements for AI agents. To support this, LangSmith provides Insights Agent, a built-in AI agent that analyzes large volumes of tracing data with minimal user configuration. It surfaces patterns and trends in agent behavior that wouldn’t be obvious from individual traces or deterministic evaluations. You’ll still ultimately have your human stakeholders review the insights report to align on next steps, but the feature jump-starts the process.
For our trading copilot, we might run an insights report automatically identifying similar conversations and clustering them into use case categories. Having a sense of the underlying themes behind the questions the traders ask the copilot can help us identify use cases we should be extra sure to support well or even future product additions that would serve our traders even better for those use cases.
As automated evaluations, human annotations, and aggregate-level insights accumulate, they provide a clear picture of how the agent performs in the real world. Those learnings feed into the final step of the cycle: restarting the iteration loop by building the agent’s next version.
Continuous refinement: turn today’s production data into tomorrow’s test suites
When you build the first version of an agent, your evaluation suite is at best educated guesses on what tests you need to validate that it works. After launch, you gain access to a much better source of test cases: real production data.
You need to curate this data into test suites that are comprehensive but not unnecessarily large. Automated systems can help generate candidate datasets, for example, by filtering production traces based on evaluator results. But we often need human judgment to curate balanced, representative evaluation sets. Evaluations can be useful running on just a few hundred examples if they’re chosen carefully, so it’s worthwhile to involve experts in deciding which examples should define the test suite.
Once our trading firm has had its copilot running in production for a while, the team will have access to real SQL queries and chatbot conversations, along with the online evaluator results and human opinions collected via monitoring and curated annotation queues.
Our team can create datasets out of the reviewed traces to run a more robust suite of evaluations, resulting in huge improvements in our agent’s performance for v2 and beyond. One of the most helpful datasets we can curate is a “golden dataset,” consisting of examples of the copilot’s best work so far, so we can use it as a baseline to ensure future versions perform at least as well. LangSmith makes this easy to put together. Use the online evaluator scores to identify candidate traces, then put them in an annotation queue so our subject matter experts can decide which ones actually belong in the golden dataset.
Conclusion
Effective agent development combines human judgment with the scalability of automated evaluations. Human expertise helps define what “good” looks like by shaping workflows, tools, context, and evaluation criteria. Automated evaluators apply that judgment at scale, helping teams test agents quickly, monitor their behavior in production, and direct human attention to the cases that matter most.
Over time, this creates a flywheel. Human feedback improves evaluators, test suites, and the agent itself, the improved agent we deploy gets us more data that tells us how to improve it, and these insights drive the next development iteration.
We used a simple use case to illustrate this process, but the same principles apply to building any agent: Build tight iteration loops, capture expert judgment in scalable evaluations, and continuously turn production data into better tests. This is the key to creating AI agents that create meaningful value for your business.