
Authored by: Aliyan Ishfaq
Coding agents are great at writing code that uses popular libraries on which LLMs have been heavily trained on. But point them to a custom library, a new version of a library, an internal API, or a niche framework – and they’re not so great. That’s a problem for teams working with domain specific libraries or enterprise code.
As developers of libraries (LangGraph, LangChain) we are really interested in how to get these coding agents to be really good at writing LangGraph and LangChain code. We tried a bunch of context engineering techniques. Some worked, some didn’t. In this blog post we will share the experiments we ran and learnings we had. Our biggest takeaway:
High quality, condensed information combined with tools to access more details as needed produced the best results
Giving the agent raw documentation access didn’t improve performance as much as we hoped. In fact, the context window filled up faster. A concise, structured guide in the form of Claude.md always outperformed simply wiring in documentation tools. The best results came from combining the two, where the agent has some base knowledge (via Claude.md) but can also access specific parts of the docs if it needs more info.
In this post, we’ll share:
- The different Claude Code configurations we tested
- The evaluation framework we used to to assess the generated code (a template you can reuse for your own libraries)
- Results and key takeaways
Claude Code Setups
We tested four different configurations, using Claude 4 Sonnet as the model for consistency:
Claude Vanilla: Out-of-the-box Claude Code with no modifications.
Claude + MCP: Claude Code connected to our MCPDoc server for documentation access.
Claude + Claude.md: Claude Code with a detailed Claude.md file containing LangGraph-specific guidance.
Claude + MCP + Claude.md: Claude with access to detailed Claude.md and MCPDoc server.
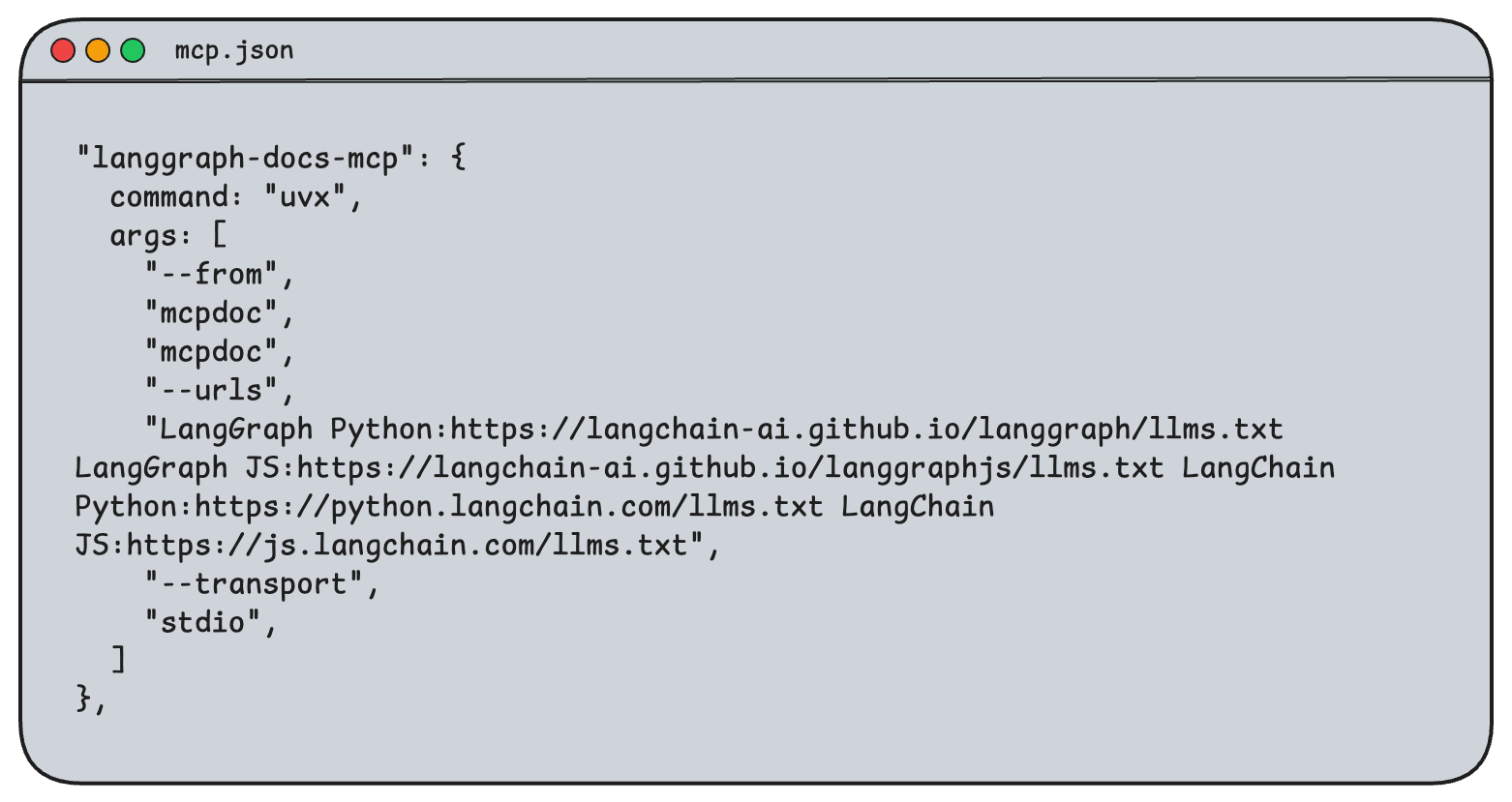
MCP tool for documentation
We built the MCPDoc server because we wanted to provide coding agents with access to any library’s documentation. It is an open-source MCP server that exposes two tools: list_doc_sources and fetch_docs. The first shares the URLs of available llms.txt files, and the latter reads a specific llms.txt file. In our setup, we provided access to LangGraph and LangChain Python and JavaScript documentation. You can easily adapt this for your use case by passing in the URLs of your library's llms.txt files in the MCP config.
Claude.md
For Claude.md, we created a LangGraph library guide. It included detailed instructions for common LangGraph project structure requirements, like mandatory codebase searching before creating files, proper export patterns, and deployment best practices. It included sample code for primitives required for building both single and multi-agent systems, things like create_react_agent, supervisor patterns, and swarm patterns for dynamic handoffs. There were certain implementations that LLMs were struggling with like streaming and human-in-the-loop for user-facing agents. We added extensive guidelines for these.
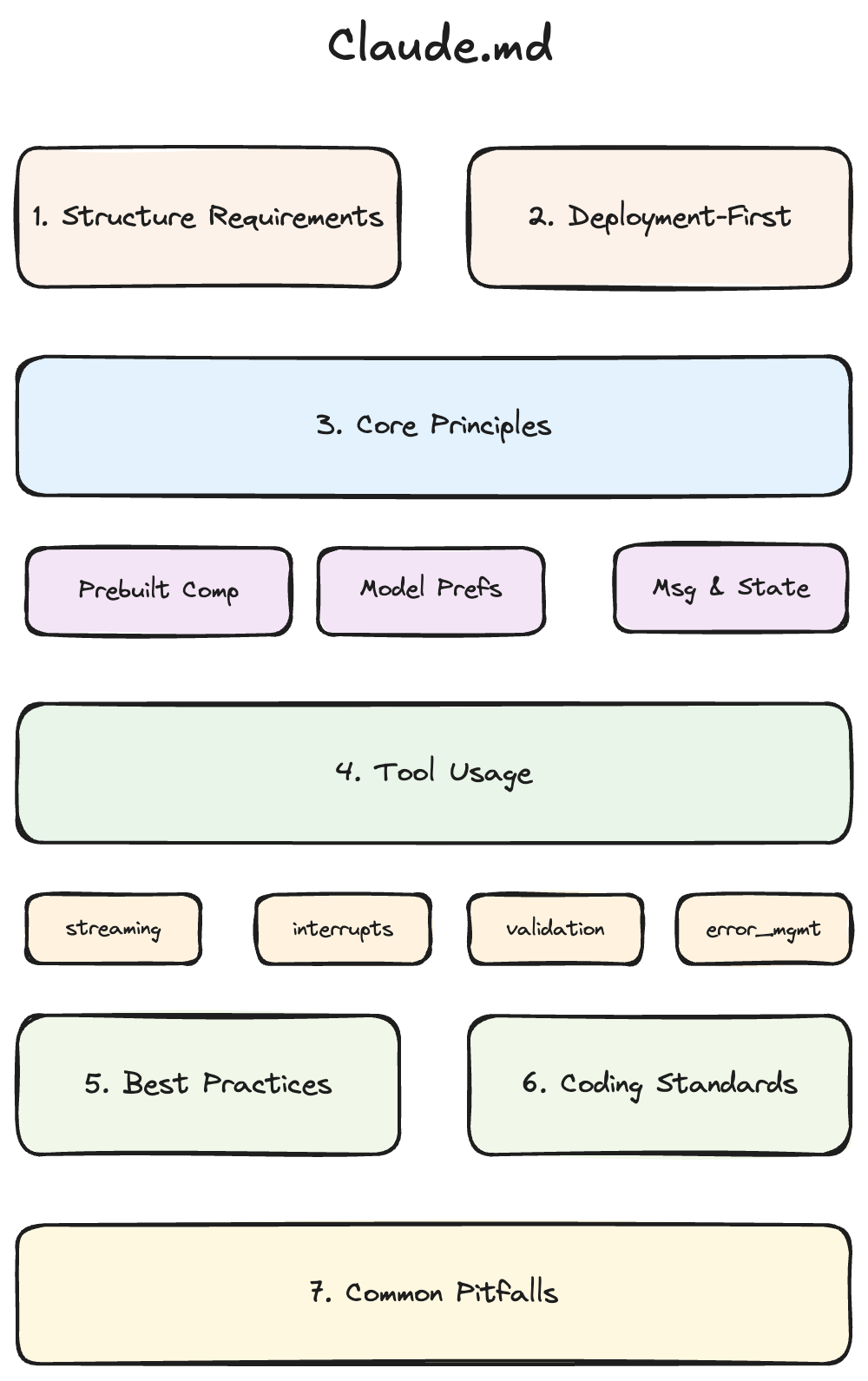
We found it particularly valuable to include comprehensive sections on common pitfalls and anti-patterns. This covered common mistakes like incorrect interrupt() usage, wrong state update patterns, type assumption errors, and overly complex implementations. These were mistakes we frequently saw LLMs make, either due to deprecated libraries or confusion with patterns from other frameworks.
We also included LangGraph-specific coding standards like structured output validation, proper message handling, and other framework integration debugging patterns. Since Claude has access to web tools, we added specific documentation URLs at the end of each section for further reference and navigation guidelines.
The way this file differs from llms.txt is that the former is a plain text file of all the content of a page with URLs while this includes condensed information that is most important when starting from scratch. As we'll see in the results, when llms.txt is passed alone, it is not most effective as it sometimes confuses LLMs with more context and no instructions on how to navigate and discern what's important.
Before going into how our Claude Code configurations performed across different tasks, we want to share our evaluation framework that we used to determine task fulfillment and code quality.
Evaluations
Our goal was to measure what contributes most to code quality, not just functionality. Popular metrics like Pass@k capture functionality and not best practices, which varies by context.
We built a task-specific evaluation harness that checks both technical requirements and subjective aspects such as code quality, design choices, and adherence to preferred methods.
We define three categories for our evaluation:
Smoke Tests
These verify basic functionality. Tests confirm that the code compiles, exposes the .invoke() method, handles expected input states, and returns expected output structures like AIMessage objects with required state properties.
We calculate scores using weighted summation:
Score = Σᵢ wᵢ × cᵢ
where wi is the weight of of test i and ci is the binary result of a test.
Task Requirement Tests
These verify task specific functionality. Tests include validation of deployment configuration files, verification of HTTP requests to external APIs such as web search or LLM providers, and unit tests specific to each coding task. Scoring is done through weighted summation of each test result, same as smoke tests.
Code Quality & Implementation Evaluation
For this category, we use LLM-as-a-Judge to capture what binary tests miss. Implementations that follow better approaches should score higher than those that simply compile and run. Code quality, design choices, and use of LangGraph abstractions all require nuanced evaluation.
We reviewed expert written code for each task and built task specific rubrics. Using Claude Sonnet 4 (claude-sonnet-4-20250514) at temperature 0, we evaluated generated code against these rubrics, using expert-written code as the reference and human annotations to log compilation and runtime errors.
Our rubric had two types of criteria:
Objective Checks: These are binary facts about the code (e.g. presence of specific nodes, correct graph structure, module separation, absence of test files). The LLM judge returned a boolean response for each check and we used weighted summation, same as smoke tests, to get a score for objective checks.
Subjective Assessment: This is qualitative evaluation of the code using expert-written code as reference and human annotation for passing in logs of compilation and runtime errors. LLM judge identified issues and categorized them by severity (critical, major, minor) across two dimensions: correctness violations and quality concerns.
We use penalty-based scoring for this:
Score = Scoreₘₐₓ - Σₛ (nₛ × pₛ)
where Scoremax is the maximum possible score, ns is the number of violations at severity s and ps is the penalty weight for that severity.
The overall score, combining both objective and subjective results, is given as:
Score = Σᵢ wᵢ × cᵢ + Σₛ (Scoreₘₐₓ,ₛ - Σₛ (nₛ × pₛ))
where the first term represents objective checks and the second term represents assessments across all subjective categories.
We ran each Claude Code configuration three times per task to account for variance. For consistency, all scores are reported as percentages of total possible points and then averaged across tasks.
You can replicate this approach for your own libraries using the LangSmith platform to compare coding agent configurations.
Results
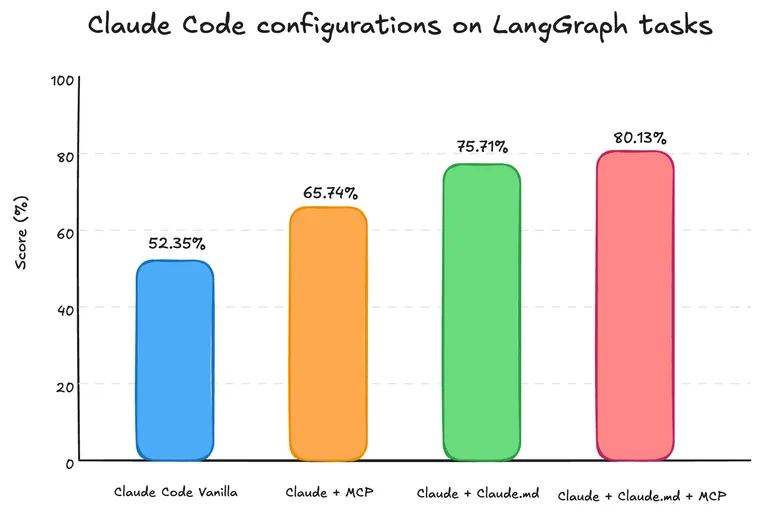
We average scores across three different LangGraph tasks to compare Claude Code configurations. The chart below shows overall scores:
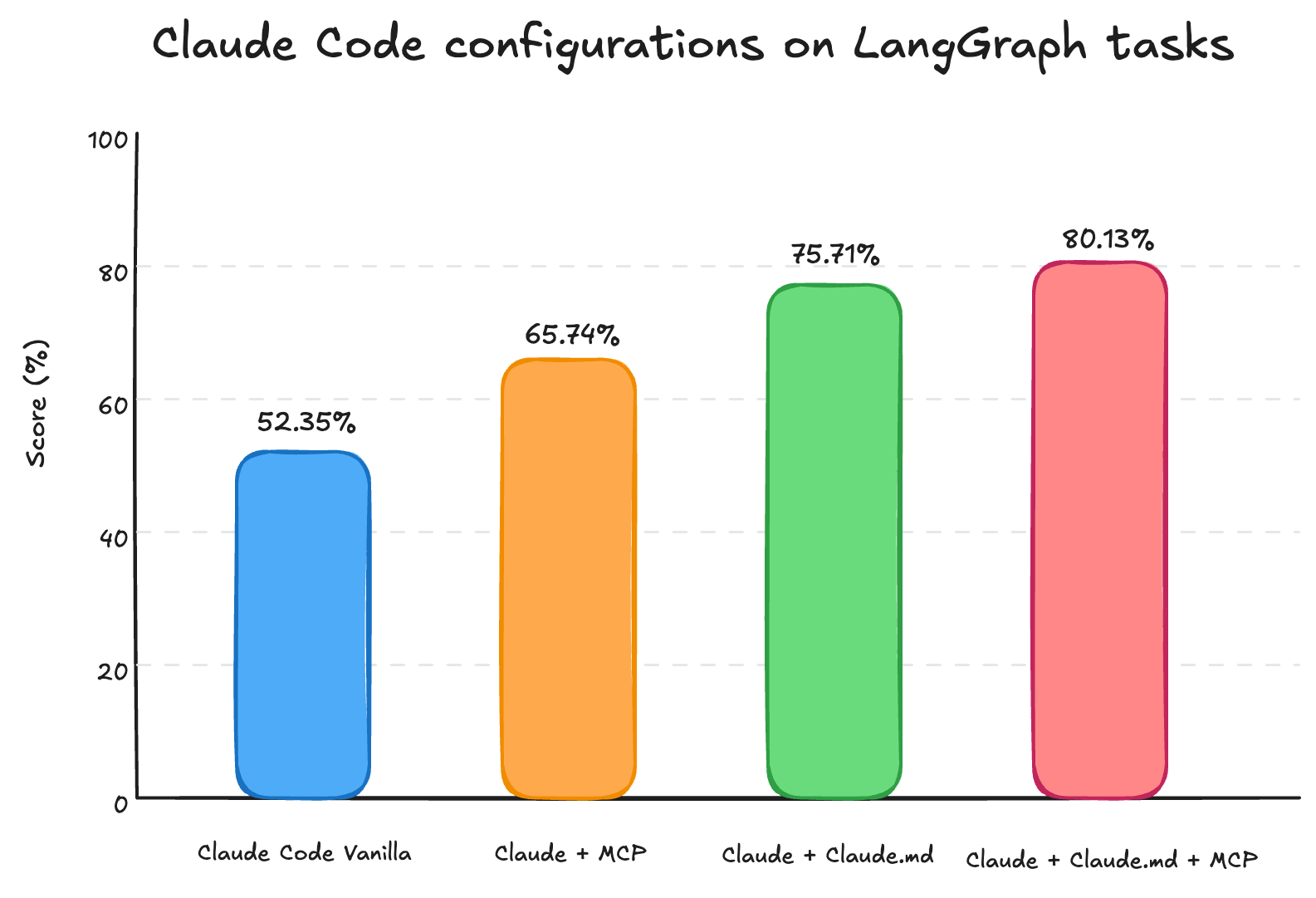
The most interesting finding for us is that Claude + Claude.md outperformed Claude + MCP, even though Claude.md only included a subset of what the MCP server could provide. Traces explained why: Claude didn’t invoke MCP tools as much as we’d expected. Even when a task required following two or three linked pages, it typically called MCP once and stopped at the main page, which only gave surface-level descriptions, not the details needed.
By contrast, Claude + Claude.md + MCP used the docs more effectively. We observed in traces that it called MCP tools more frequently and even triggered web search tool when required. This behavior was driven by Claude.md that included reference URLs at the end of each section to look for further information.
This doesn’t mean MCP tools didn’t help on their own. They improved scores by ~10 percentage points, mainly by grounding the agent in basic syntax and concepts. But for task completion and code quality, Claude.md was more important. The guide included pitfalls to avoid and principles to follow, which helped Claude Code think better and explore different parts of the library rather than stopping at high-level descriptions.
These results point to a few broader lessons for anyone configuring coding agents.
Key Takeaways
The results leave us with a few takeaways. If you’re thinking about customizing coding agents for your own libraries, the following can be useful:
Context Overload: Dumping large llms.txt files from documentation can crowd the context window. This can lead to poor performance and higher cost. Our MCP server has a naive implementation of fetching page contents completely. Even invoking it once flagged Claude Code warnings of context window filling up. If your documentation is extensive enough that you need tooling to retrieve specific docs, it’s worth building smarter retrieval tooling that pulls only the relevant snippets.
Claude.md has the highest payoff: It’s easier to set up than an MCP server or specific tooling and cheaper to run. On task #2, Claude + Claude.md was ~2.5x cheaper than Claude MCP and Claude + Claude.md + MCP. It’s cheaper than Claude MCP and performs better. This is a great starting point when thinking of customizing Claude Code and may just be good enough for some use cases.
Write good instructions. A Claude.md (or Agents.md) should highlight core concepts, unique functionality, and common primitives in your library. Review failed runs manually to find recurring pitfalls and add guidance for them. For us, that meant covering async tasks in LangGraph with Streamlit, where agents often failed on asyncio integration. We also added debugging steps for spinning up dev servers, which fixed import errors and let Claude Code send requests to the server to verify outputs. Popular code-gen tools often use long system prompts (7–10k tokens). Putting effort into instructions pays off pretty well.
Claude + Claude.md + MCP wins: While Claude.md provides the most mileage per token, the strongest results came from pairing it with an MCP server that allows it to read documentation in detail. The guide provided orientation with concepts and the docs helped go in-depth. Together, they can produce best results on domain specific libraries.
In the Appendix, we include per-task results and category-level graphs for readers who want to dig into per task performance.
Appendix
Task #1: Text-to-SQL Agent
We asked each configuration to build a LangGraph-based text-to-SQL agent that could generate SQL query from natural language, execute it against a database, and return a natural language response. This task required fetching the Chinook SQLite database from a remote URL and setting up an in-memory database. You can read the prompt that we passed to Claude Code instances here.
For this task, our smoke tests verified basic LangGraph functionality. Task requirements checked database setup; SQL query handling for simple queries, join queries, date range queries; and LLM-as-a-Judge evaluated code design choices such as remote URL fetching, separate nodes for SQL generation, execution, and response. The LLM-as-a-Judge prompt is available here.
The results show performance difference across Claude Code configurations and categories:
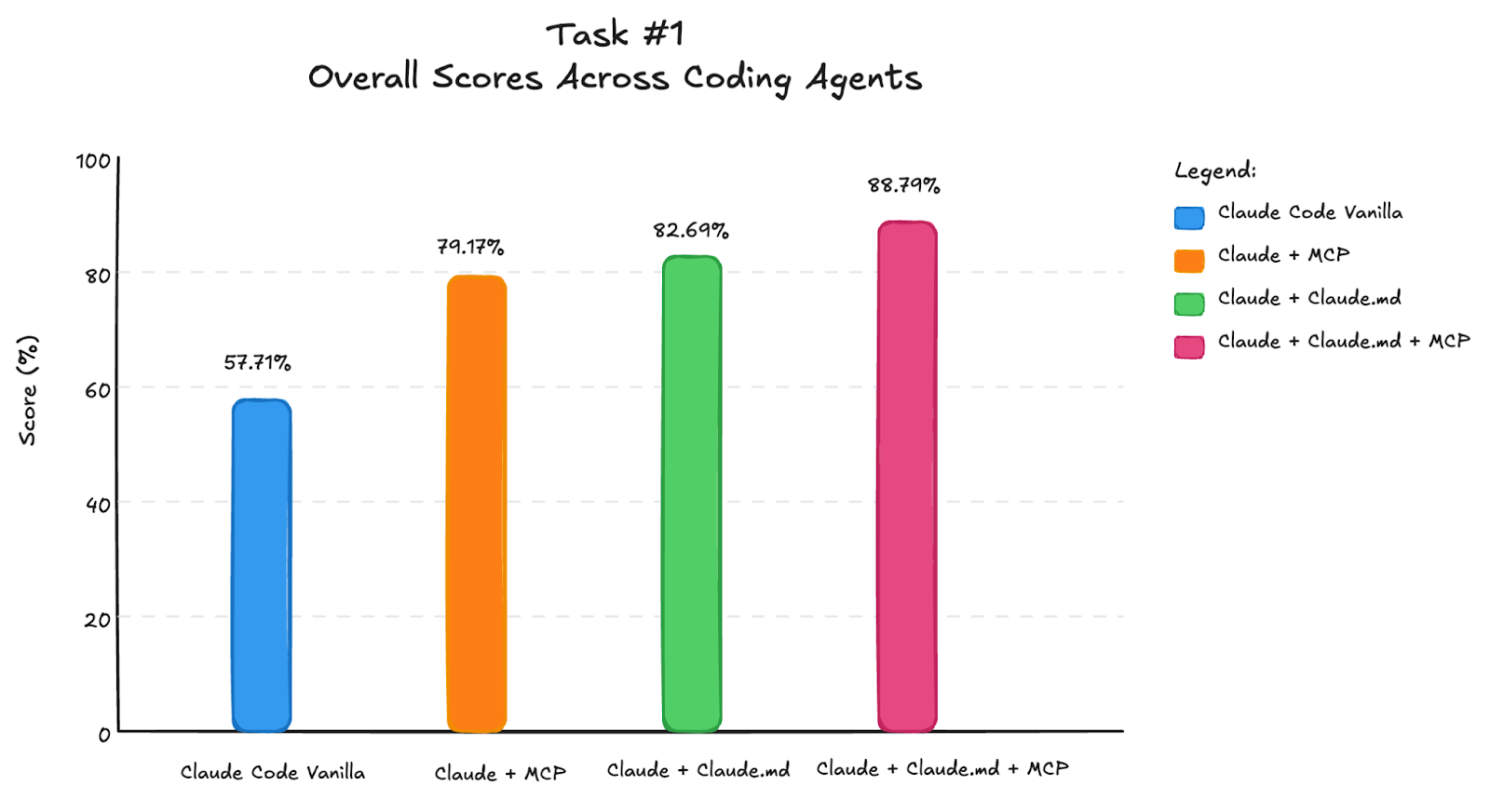
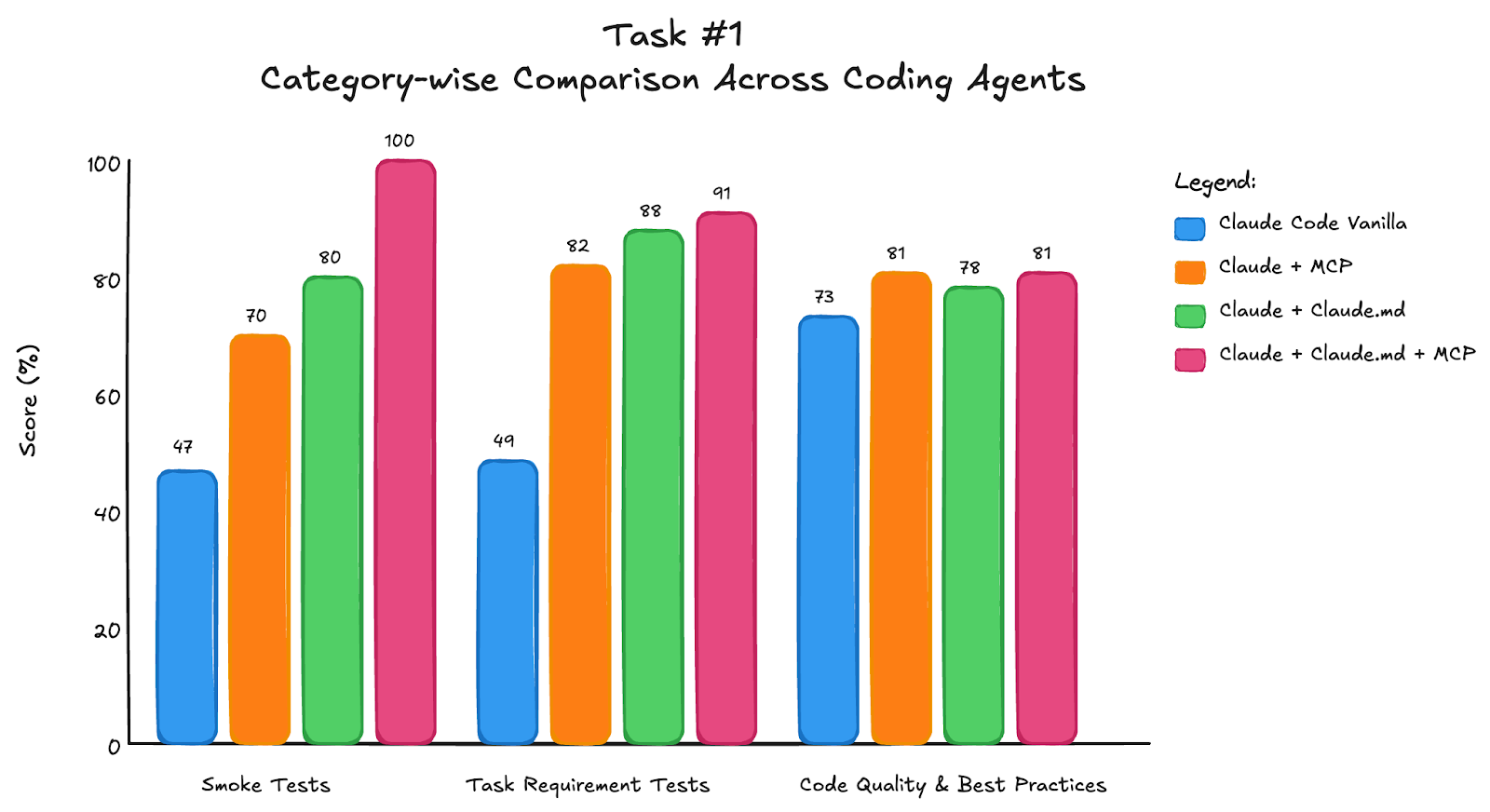
Poor implementations typically struggled with connecting in-memory database across threads, downloaded and hardcoded schemas in LLM prompts instead of using remote URLs with runtime schema reading, and failed to properly parse LLM output for SQL execution (breaking when LLM would generate slightly different formatted results).
Task #2: Company Researcher
For this task, we asked each Claude configuration to build a multi-node LangGraph agent that researches companies using web search through Tavily API. The agent needed to handle structured data collection, implement parallel search execution, and add a reflection step that ensures all requested information is gathered. You can read the prompt here.
Our tests verified basic functionality, Tavily API integration, and presence of all requested properties in the structured object class. LLM-as-a-Judge checked for implementation of features like reflection logic, minimum search query limits, and parallel web search execution.
The following are the results for this task:
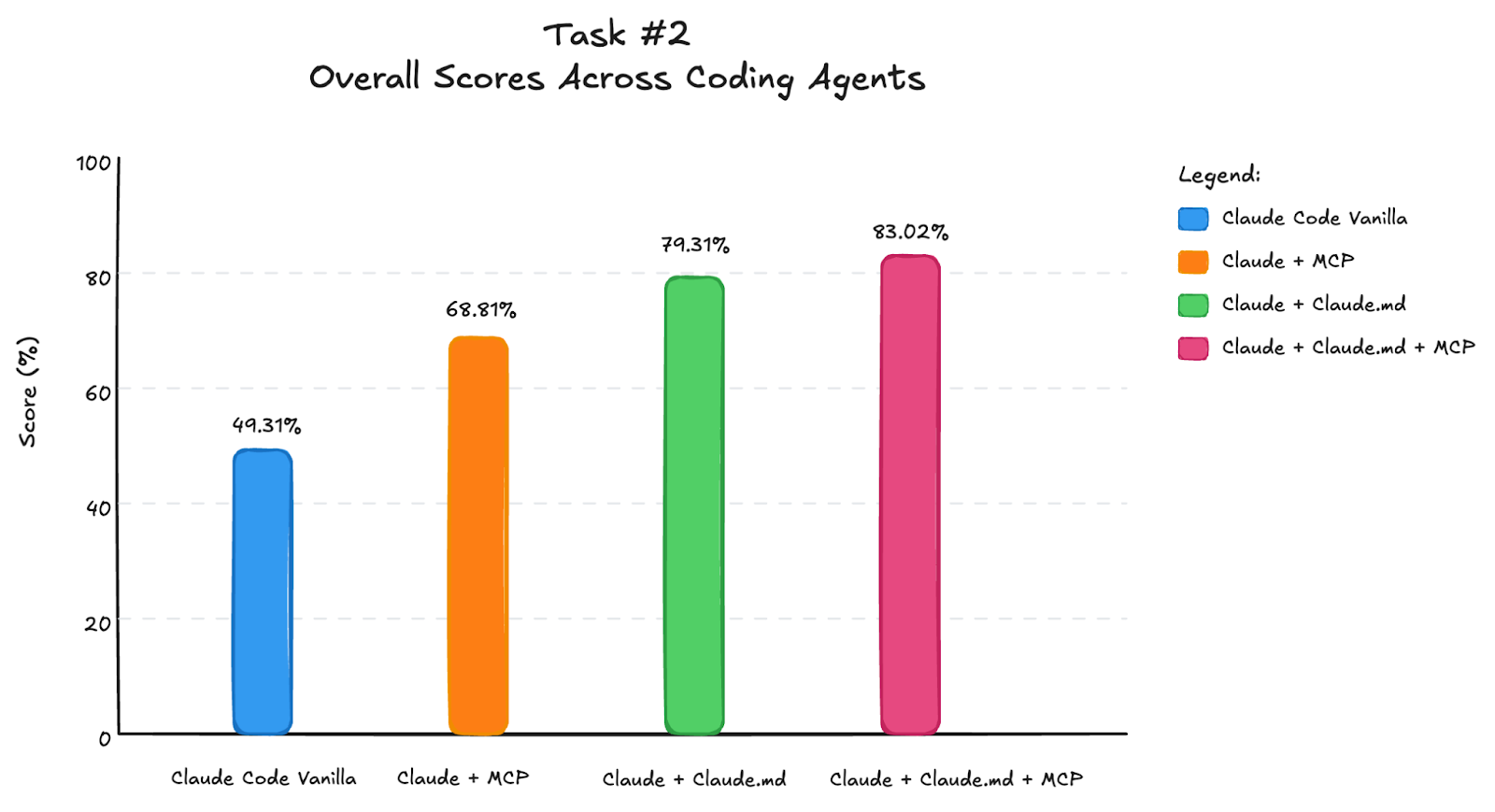
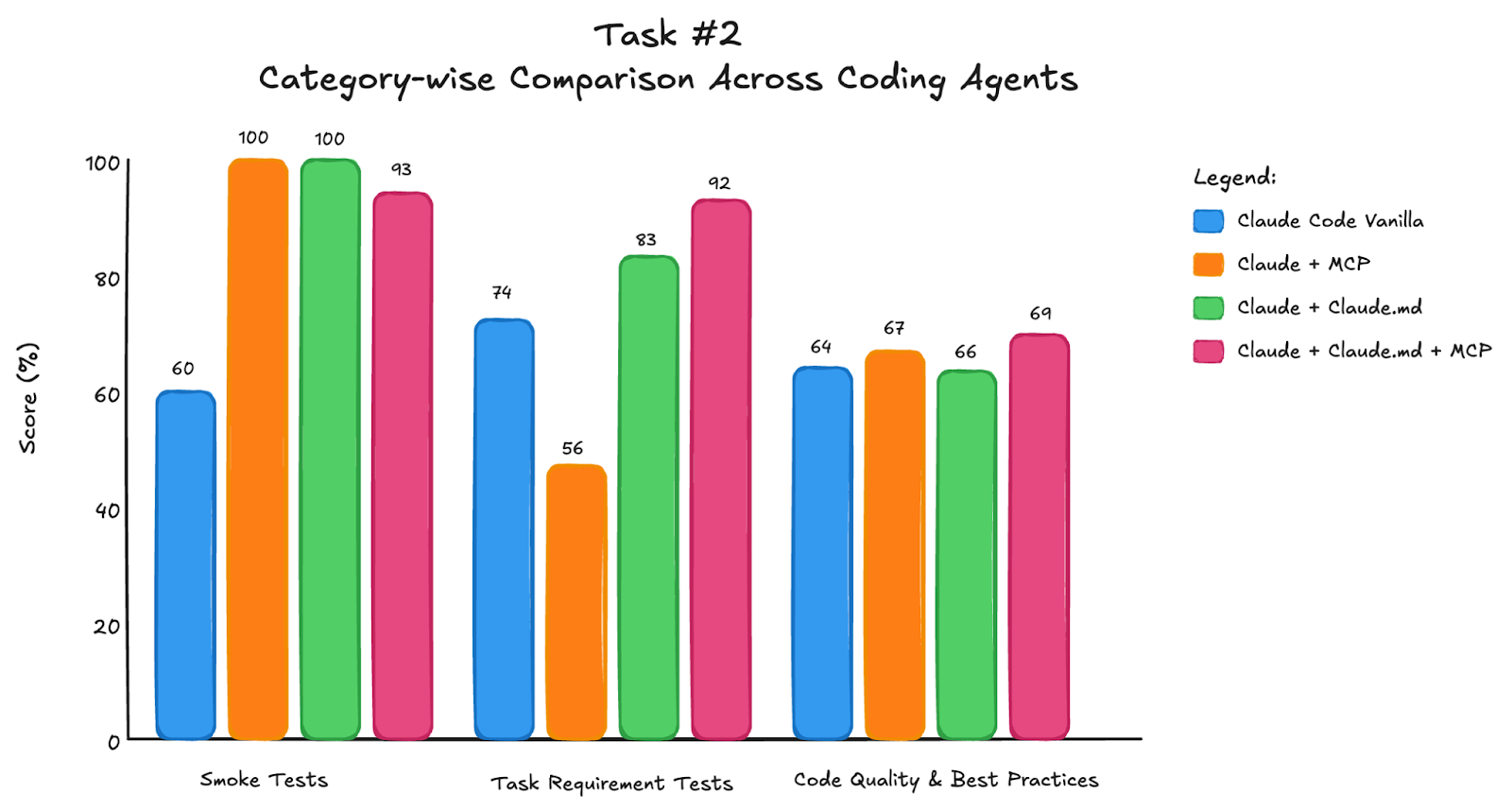
Most implementation failures were related to structuring information in an object in state and reflection step. Poor implementations either didn’t have functional reflection nodes or failed to trigger additional searches.
Task #3: Categories of Memories
This was an editing task where we provided each Claude Code configuration with an existing memory agent as base code. We asked them to extend the memory storage method to categorize memory by type (personal, professional, other) in addition to user ID, implement selective memory retrieval based on message category instead of just user ID, and add human in the loop confirmation step before saving memories. We deliberately added syntax errors as well. The full prompt is available here.
With tests we verified that implementations correctly added the interrupt functionality before memory storage, implemented category-wise storage and retrieval, used three specific categories (personal, professional, other), and maintained functional interrupt logic that saves memories only when users accept. LLM-as-a-Judge evaluated whether implementations used LLM-based categorization rather than brittle keyword matching and unnecessary files.
For an editing task, we see following results:
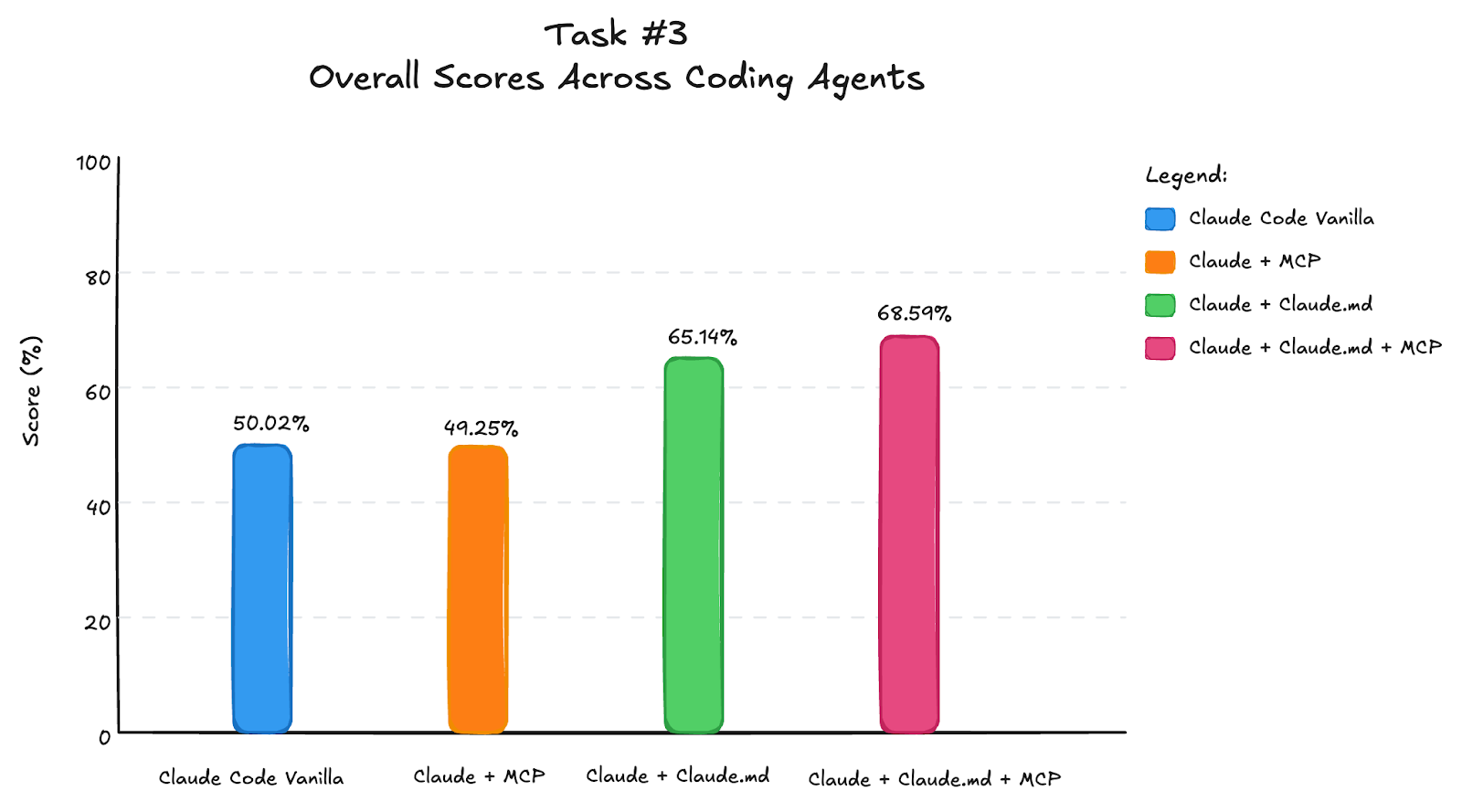
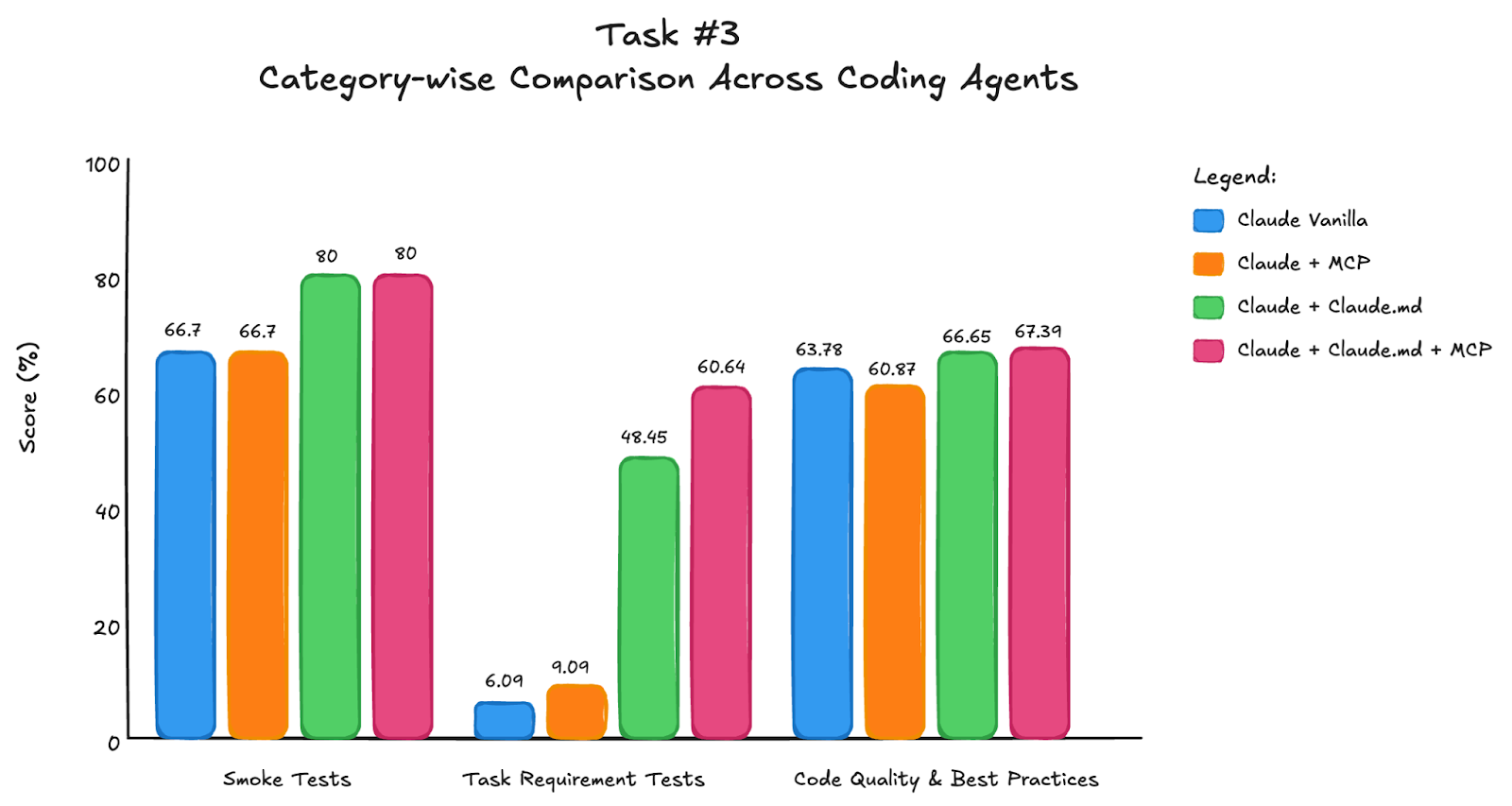
Most implementations struggled with correctly implementing interrupt functionality. Wrong implementations either added simple input() calls to get terminal input or overcomplicated the solution by creating separate nodes instead of using a few lines of proper interrupt logic. Poor implementations also relied on keyword matching for categorization instead of LLM-based classification, and almost all failed to catch the deliberate syntax errors we included.