

Guest blog post by Ilya Yudkovich and Nick Roshdieh
In the era of AI agents, searching efficiently through S&P Global's vast data estate presents a unique set of challenges. As S&P Global’s engine for AI innovation and transformation, Kensho’s goal is to ensure that as AI transforms industries, its outputs remain grounded in trusted data–however and wherever customers choose to use it.
Kensho’s team of engineers, researchers, and builders are focused on applying advanced AI and machine learning across S&P Global’s rich datasets to unify the data retrieval process, providing customers a single interface to bring this intelligence into AI applications and agentic workflows.
Unlike the textual information typical of many web-based search applications, S&P Global data is highly structured and nuanced. This requires employing advanced data retrieval techniques to effectively integrate our data with cutting-edge generative AI applications. To solve this challenge, we developed Grounding, a multi-agent framework that serves as a core access layer for S&P Global data.
Grounding ensures that every insight is derived directly from verified datasets. The framework, developed using several LangGraph tools, is a foundational solution for unifying data from multiple business units and integrating that data with AI agents, LLMs, and GenAI applications while maintaining high-trust validity and compliance.
The Challenge: Fragmented Financial Data Retrieval
Financial professionals often struggle with data retrieval across fragmented systems, spending hours locating and verifying information that they need to analyze earnings, retrieve financial metrics, perform market research, and more. Kensho’s Grounding system simplifies this process by creating a single entry point for natural language queries against S&P Global's verified financial datasets. This eliminates the need to navigate complex database schemas or learn specialized query languages. Through Grounding, clients can access accurate real-time financial information with citation-backed responses to verified S&P Global data sources, ensuring high-trust validity and compliance with transparency and traceability in every result. This pattern enables users to focus on analysis rather than data access hunting and source validation.
Designing a Multi-Agent Framework with LangGraph
We architected our Grounding system as a centralized entry point for data access across our AI agents, which retrieve data from an array of cross-divisional S&P Global data sources stemming from various data repositories. Rather than embedding natural language parsing logic into individual agents, our router intelligently directs queries to specialized Data Retrieval Agents (DRAs) owned by different data teams such as equity research, fixed income, macroeconomics to name a few domains. This provides a separation of concern between data routing and data retrieval layers, supporting parallel ownership of each.
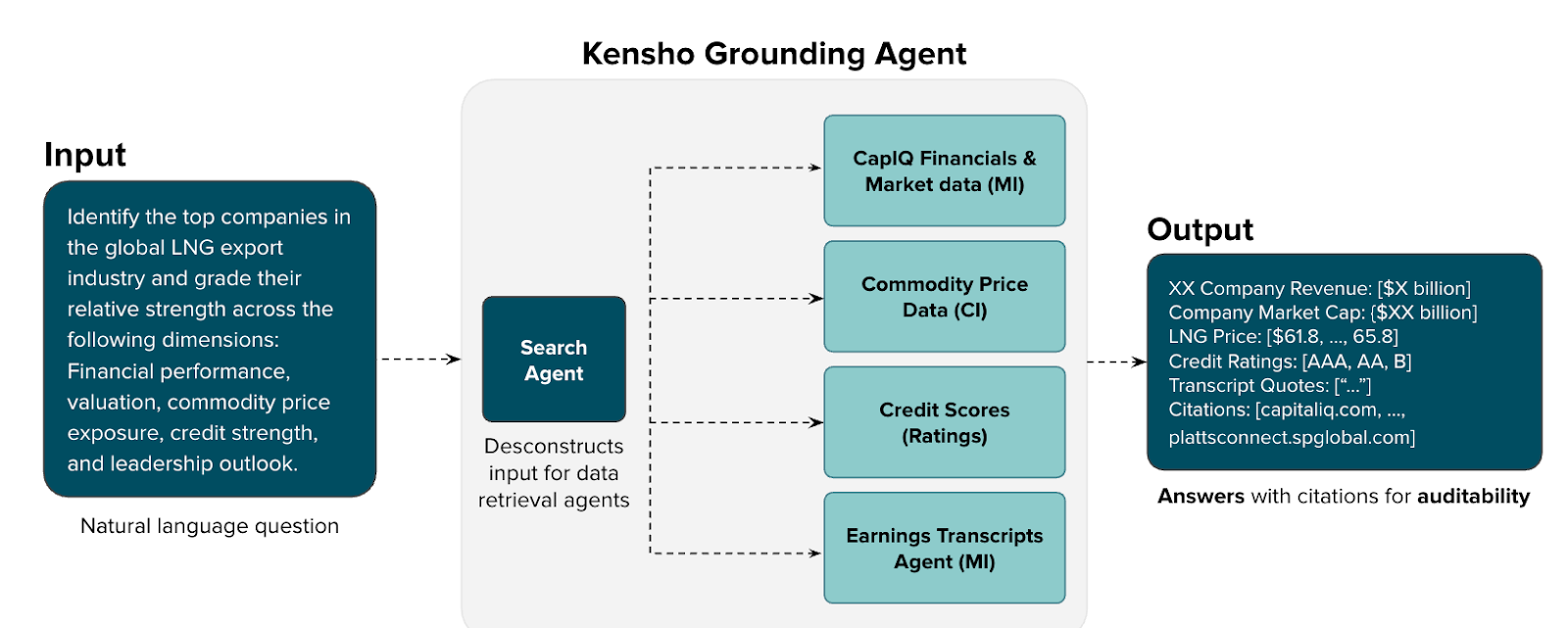
The DRAs are meant to provide a single responsibility vertical, increasing the signal-to-noise ratio for queries using that dataset. The aggregation layer within the router then solves the map-reduce problem: taking distributed responses from multiple DRAs and intelligently combining them into coherent, actionable insights that maintain both accuracy and context.
LangGraph is the engine behind the Grounding router. Its core responsibilities include providing access to the diverse agents based on relevant context from the user query, breaking down a query into smaller DRA-specific sub-queries, and aggregating the responses back to the user. LangGraph’s design made it easy to iterate and test the router locally, providing that single entry point and ensuring a smooth developer experience.
Establishing a Custom Data Retrieval Protocol
Distributed data and AI systems often suffer from inconsistent communication interfaces. These can lead to unreliable agent interactions and create complex data processing needs for each individual agent. Through our team’s early internal experimentation, we developed a custom DRA protocol to ensure consistent data access patterns.
The protocol established a common data format for all returned data, including both structured and unstructured data. This has accelerated collaboration and consistent data exchange across our entire multi-agent ecosystem as we work across S&P Global to develop and deploy DRAs connected to Grounding.
Architecting the protocol in this way, centralized through our Grounding system, has enabled Kensho to rapidly deploy multiple specialized financial AI products ( i.e. agents and APIs), each leveraging the same robust data foundation. From our equity research assistant–which helps analysts compare sector performance–to our ESG (Environmental, Social, and Governance) compliance agent that tracks sustainability metrics, all applications share the same reliable data access layer. Building agents and products atop a consistent system accelerates our time-to-market giving newly created agents immediate access to the full breadth of S&P Global data without rebuilding data pipelines.
Key Learnings for an Evolving Agentic Ecosystem
The process of building and refining our multi-agent framework left the Kensho team with a few key insights. We hope these best practices will help guide other organizations when developing complex multi-agent architectures:
1. Observability: Comprehensive tracing and deliberate metadata requirements are essential for maintaining visibility into agent behavior and enabling effective debugging and optimization at scale. Our custom protocol allows us to package the necessary information across our distributed multi-agent system. Native embedded LangGraph integration is a critical component for maintaining our distributed systems and ensuring end-to-end traceability and debugging for developers.
2. Multi-stage evaluation: The financial industry requires high trust and certainty in financial data retrieval. Evaluating our federated agent system requires multi-faceted matrices evaluating routing decisions, data quality, and answer completeness at each step of the multi-agent retrieval. The evaluation suite executes test queries through the LangGraph-based RouterGraph. We measure accuracy against selected agents and various data agents, focusing on exact-match (selected the correct agents and retrieved expected responses) and tool-calling (whether the router selected the right tools, but got various responses). This allowed us to evaluate accuracy and identify gaps within our system.
3. Protocol studies and optimization: We continuously analyze user and agent interaction patterns, which enables iterative refinement of Kensho’s custom protocol. This has significantly improved system efficiency, maximizing the output format for both direct LLM contextual understanding as well as programmatic processing–all while maintaining the reliability that financial services demand.