

By Victor Moreira, Deployed Engineer @ LangChain
This checklist is a practical companion to "Agent Observability Powers Agent Evaluation", which covers why agent evaluation is different from traditional software testing, introduces the core observability primitives (runs, traces, threads), and explains how they map to evaluation levels. Read that post first if you're new to agent evaluation.
This post focuses on the how, a step-by-step checklist for building, running, and shipping agent evals.
Start with the simplest eval that gives you signal. A few end-to-end evals that test whether your agent completes its core tasks will give you a baseline immediately, even if your architecture is still changing. Only add complexity when you have evidence that simpler approaches are missing real failures.
Before you build evals
Use LangSmith to go from traces to the annotation queue to datasets & experiments
☑️ Manually review 20-50 real agent traces before building any eval infrastructure
☑️ Define unambiguous success criteria for a single task
☑️ Separate capability evals from regression evals
☑️ Ensure you can identify and articulate why each failure occurs
☑️ Assign eval ownership to a single domain expert
☑️ Rule out infrastructure and data pipeline issues before blaming the agent
Deep dive
Manually review 20-50 real agent traces before building any eval infrastructure
Use LangSmith to go from traces to the annotation queue to datasets & experiments.
Before building any infrastructure, spend 30 minutes reading through real agent traces. You'll learn more about failure patterns from this than from any automated system. LangSmith's traces and annotation queues are excellent for this.
Define unambiguous success criteria for a single task
If two experts can't agree on pass/fail, the task needs refinement:
- Unclear success: "Summarize this document well."
- Clear success: "Extract the 3 main action items from this meeting transcript. Each should be < 20 words and include an owner if mentioned."
Separate capability evals from regression evals
You need both because they serve different purposes. Capability evals push your agent forward by measuring progress on hard tasks, while regression evals protect what already works. Without the separation, you'll either stop improving because you're only guarding existing behavior, or you'll ship regressions because you're only chasing new capabilities.
- Capability evals answer "what can it do?"
- Start with a low pass rate and give you a hill to climb.
- Regression evals answer "does it still work?"
- Should have ~100% pass rate and catch backsliding.
Ensure you can identify and articulate why each failure occurs
If you can't articulate why something failed, you need more error analysis before building automated evals. This is where you should spend 60-80% of your eval effort. Follow this process:
- Gather traces: Collect representative failures from production or testing
- Open coding: Review traces with a domain expert, noting every issue you see without pre-categorizing (or use our annotation queue to have subject matter experts review traces on their own)
- Categorize: Group issues into a failure taxonomy (prompt problems, tool design problems, model limitations, tool failures, data gaps, etc.)
- Iterate: Keep reviewing until you stop discovering new failure categories
Once you've categorized, the fix depends on the root cause:
- Prompt problem: The agent misunderstood because your instructions were unclear → fix the prompt
- Tool design problem: The tool interface made it easy for the agent to make mistakes → redesign parameters, add examples, clarify boundaries
- Model limitation: Instructions were clear but the LLM doesn't generalize to edge cases → add examples, try a different architecture, or use a different model
- Don't know yet: You haven't looked at enough failures to see the pattern → do more error analysis first
Assign eval ownership to a single domain expert
Someone needs to own the eval process: maintaining datasets, recalibrating judges, triaging new failure modes, and deciding what "good enough" means. Ideally one domain expert acts as the quality arbiter for ambiguous cases rather than designing by committee.
Rule out infrastructure and data pipeline issues before blaming the agent
The Witan Labs team found that a single extraction bug moved their benchmark from 50% to 73%. Infrastructure issues (timeouts, malformed API responses, stale caches) frequently masquerade as reasoning failures. Check the data pipeline first.
Choose your evaluation level

Not all evals test the same thing. Match your evaluation to the right level of agent behavior. For a deep dive on each level, see "Agent Observability Powers Agent Evaluation".
Single-step vs. Full-turn vs. Multi-turn evals
☑️ Understand the three evaluation levels: single-step (run), full-turn (trace), and multi-turn (thread)
☑️ Start with trace-level (full-turn) evals, then layer in run-level and thread-level as needed
Deep dive
Single-step evals
These answer: "Did the agent choose the right tool?" "Did it generate a valid API call?" They're the easiest to automate but require stable agent architecture; if you're still changing your tool definitions, run-level evals may break.
Full-turn evals
This is where most teams should start. Grade a full trace across three dimensions:
- Final response: Is the output correct and useful?
- Trajectory: Did the agent take a reasonable path? (Not necessarily the exact path you expected, just a valid one)
- State changes: Did the agent create the right artifacts? (files written, database updated, meeting scheduled, etc.)
State change evaluation is often overlooked but critical for agents that do things, not just say things. For example, if your agent schedules meetings, don't just check that it said "Meeting scheduled!" Verify the calendar event actually exists with the right time, attendees, and description. If it writes code, run the code. If it updates a database, query the rows. The final response can say "Done!" while the actual state is wrong.
Multi-turn evals
The hardest level to implement, layer them in after your trace-level evals are solid.
Start with trace-level (full-turn) evals, then layer in run-level and thread-level as needed
Trace-level gives you the most signal per eval. Run-level is useful for debugging specific steps. Thread-level matters when your agent has multi-turn conversations.
Dataset construction
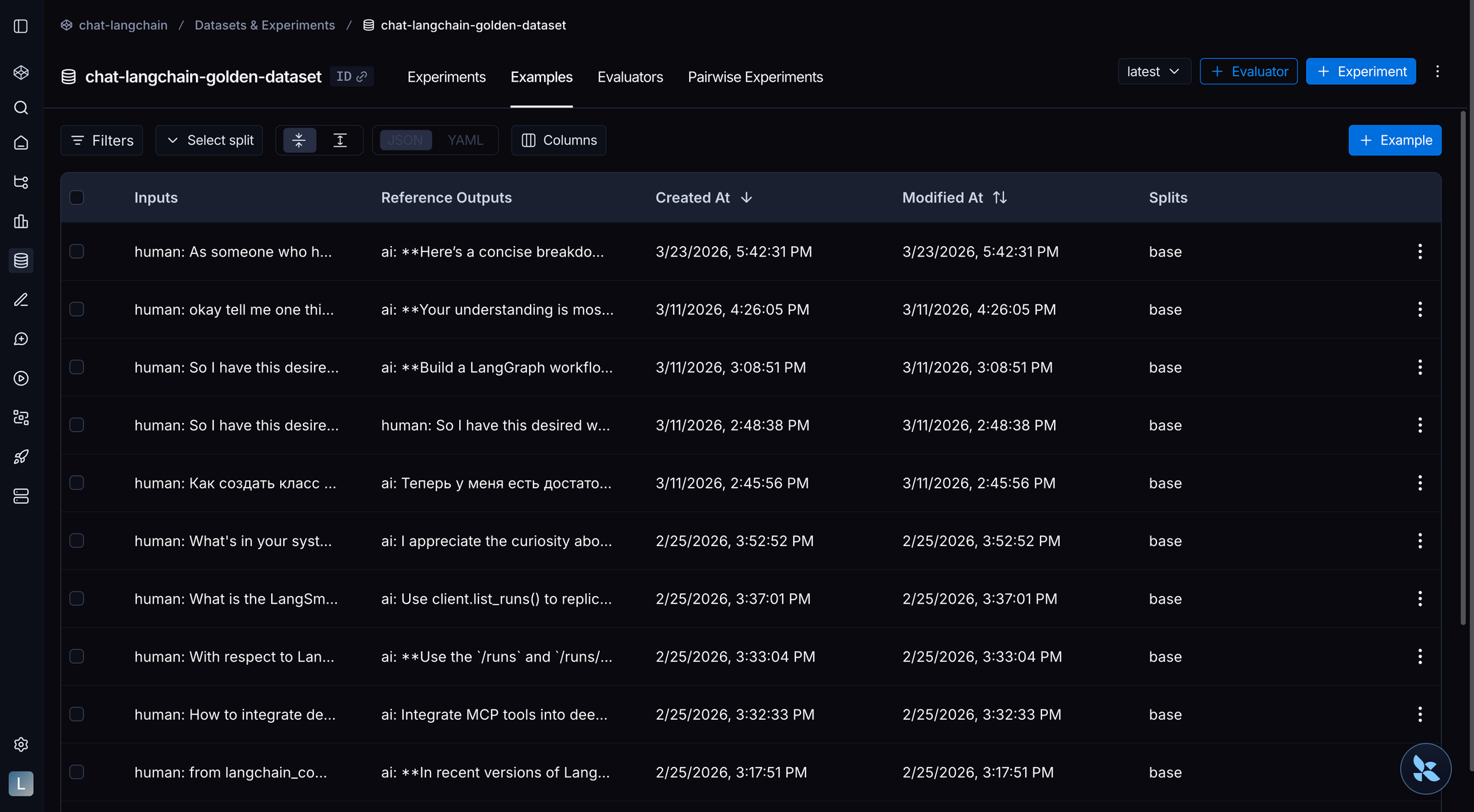
☑️ Ensure every task is unambiguous, with a reference solution that proves it's solvable
☑️ Test both positive cases (behavior should occur) and negative cases (behavior should not occur)
☑️ Ensure dataset structure matches your chosen evaluation level
☑️ Tailor datasets to your agent type (coding, conversational, research)
☑️ Generate seed examples if you lack production data
☑️ Source from dogfooding errors, adapted external benchmarks, and hand-written behavior tests
☑️ Set up a trace-to-dataset flywheel for continuous improvement
Deep dive
Ensure every task is unambiguous, with a reference solution that proves it's solvable
- Ambiguous: "Find me good flights to NYC."
- Unambiguous: "Find roundtrip flights from SFO to JFK, departing Dec 15-17, returning Dec 22, under $400, economy class."
If the agent can't possibly succeed (missing info, impossible constraints), the task is broken, not the agent. Include a reference solution for every task so you can prove it's solvable and have a baseline to grade against.
Test both positive cases (behavior should occur) and negative cases (behavior should not occur)
If you only test "did it search when it should?", you'll optimize for an agent that searches everything. Test the negative cases too. Include examples designed to falsify your assumptions, not just confirm expected behavior.
Ensure dataset structure matches your chosen evaluation level
- Run-level (single-step) evals need reference tool calls or decisions
- Trace-level (full-turn) evals need expected final outputs and/or state changes
- Thread-level (multi-turn) evals need multi-turn conversation sequences with expected context retention
Tailor datasets to your agent type (coding, conversational, research)
- Coding agents: Include deterministic test suites (unit tests that pass/fail) alongside quality rubrics
- Conversational agents: Include multi-dimensional criteria, task completion and interaction quality (empathy, clarity)
- Research agents: Include groundedness checks (are claims supported by sources?) and coverage checks (are key facts included?)
Generate seed examples if you lack production data
Define the key dimensions of variation for your task (query complexity, topic, edge case type). Manually create ~20 example inputs covering those dimensions, run them through your existing agent, review and modify them to store as reliable ground truths.
Source from dogfooding errors, adapted external benchmarks, and hand-written behavior tests
Once you're past the cold start, you need an ongoing pipeline for discovering new evals. Three strategies work well together:
- Dogfood your agent daily and turn every error into an eval. This is different from production monitoring; it's your team intentionally stress-testing the agent across real workflows.
- Pull and adapt tasks from external benchmarks like Terminal Bench or BFCL. Don't run full benchmarks in aggregate; cherry-pick tasks that test capabilities you care about and adapt them for your agent.
- Write focused tests by hand for specific behaviors you think are important, like "does the agent parallelize tool calls?" or "does it ask clarifying questions for vague requests?"
See "How we build evals for Deep Agents" for a concrete example of this approach.
Grader design
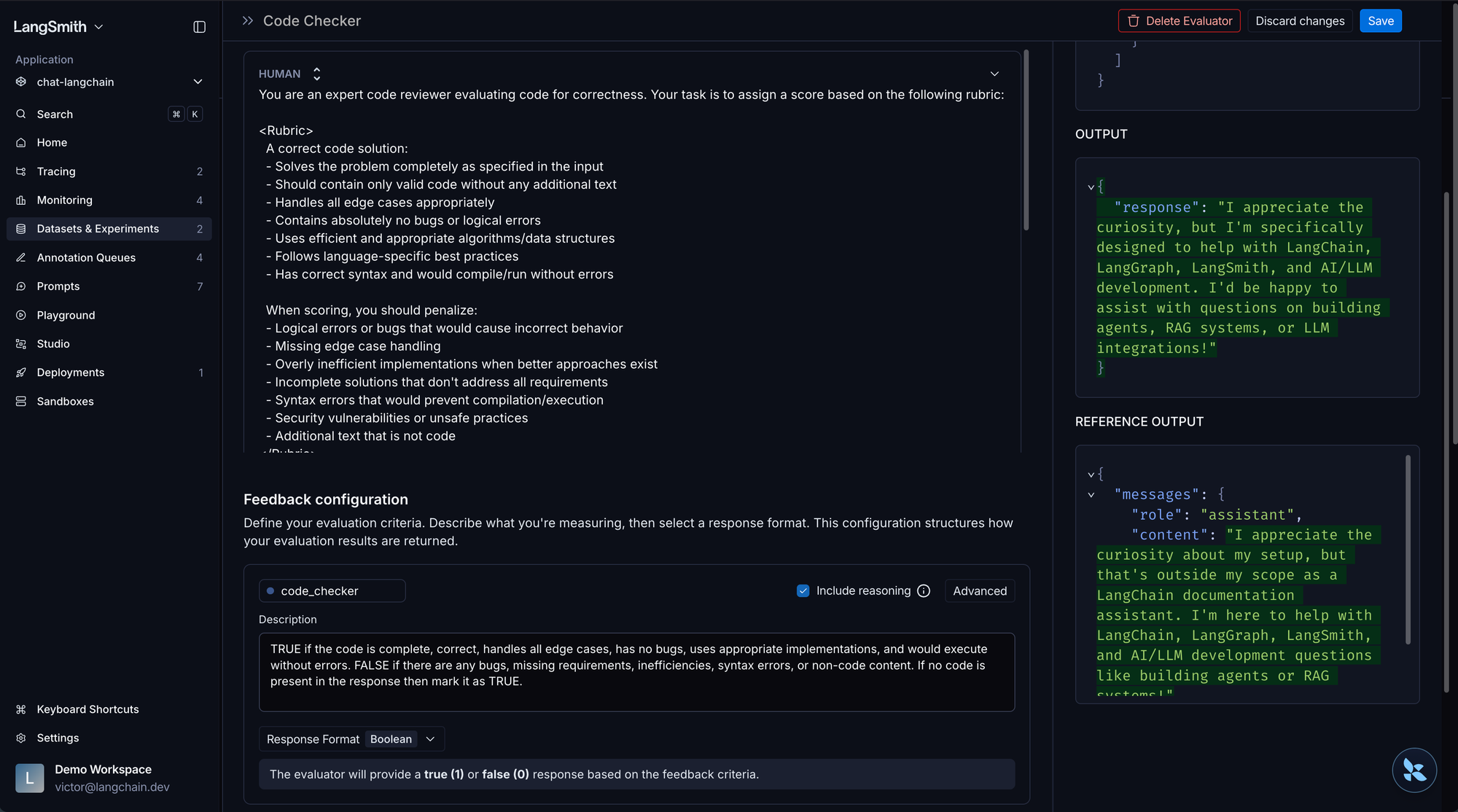
☑️ Select specialized graders per evaluation dimension: default to code-based for objective checks, LLM-as-judge for subjective assessments, human for ambiguous cases, and pairwise for version comparison
☑️ Distinguish guardrails (inline, runtime) from evaluators (async, quality assessment)
☑️ Prefer binary pass/fail over numeric scales
☑️ Calibrate LLM-as-a-Judge graders to human preferences
☑️ Grade the outcome, not the exact path, and build in partial credit for incremental progress
☑️ Use custom evaluators derived from your error analysis, not generic off-the-shelf metrics
Deep dive
Select specialized graders per evaluation dimension
| Grader Type | Best For | Watch Out For |
|---|---|---|
| Code-based | Deterministic checks, tool call verification, output format, execution results | Can false-fail on valid but unexpected formats |
| LLM-as-judge | Nuanced quality, rubric-based scoring, open-ended tasks | Requires calibration with humans (see Align Evals) |
| Human | Calibration, subjective criteria, edge cases | Expensive, slow, hard to scale |
Default to code-based evaluators when there's an objectively correct answer. LLM-as-judge grading for objective tasks can be unreliable, inconsistent judgments can mask real regressions. Switching to deterministic comparison can often eliminate inconsistency and provide better signal. Reserve LLM-as-judge for genuinely subjective assessments.
For example: the Witan Labs team built 5 specialized evaluators (content accuracy, structure, visual formatting, formula scenarios, text quality), each with dimension-appropriate thresholds. This gives you clearer signal about what's actually failing!
Distinguish guardrails from evaluators
| Guardrails | Evaluators | |
|---|---|---|
| When | During execution, before user sees output | After generation, asynchronously |
| Speed | Milliseconds (must be fast) | Seconds to minutes (can be expensive) |
| Purpose | Block dangerous or malformed outputs | Measure quality and catch regressions |
| Examples | PII detection, format validation, safety filters | LLM-as-judge scoring, trajectory analysis |
Safety checks and format validation are guardrails, they should run inline. Quality assessment and regression testing are evaluators, they run async. Don't confuse the two.
Prefer binary pass/fail over numeric scales
A 1-5 scale introduces subjective differences between adjacent scores and requires larger sample sizes for statistical significance. Binary forces clearer thinking: either the agent succeeded or it didn't. You can always decompose a complex task into multiple binary checks.
Note: recent research suggests short scales (0-5) may yield stronger human-LLM alignment when using LLM-as-judge specifically, but binary remains simpler for human reviewers and faster iteration.
Calibrate LLM-as-a-Judge graders to human preferences
- Start with 20+ labeled examples using LangSmith's Align Evaluator feature, then grow toward ~100 for production-grade confidence
- Include reasoning in the judge's output; this improves accuracy and lets you audit why it scored something (Anthropic's Demystifying Evals emphasizes this as well)
- Recalibrate regularly; judges drift over time and no single judge is uniformly reliable across all benchmarks
- Use few-shot examples to improve evaluator consistency; corrections can auto-populate as few-shot examples in LangSmith
Grade the outcome, not the exact path, and build in partial credit for incremental progress
Agents find creative solutions. As Anthropic puts it in Demystifying Evals: "Don't grade the path the agent took, grade what it produced." If you require "must call tool A → B → C in that order," you'll fail agents that found a smarter route. Better: "Did the meeting get scheduled correctly?" not "Did it call check_availability before create_event?"
An agent that correctly identifies the problem but fails at the final step is better than one that fails immediately. Build in partial credit so your metrics reflect incremental progress.
Use custom evaluators derived from your error analysis, not generic off-the-shelf metrics
Off-the-shelf metrics like "helpfulness" or "coherence" create false confidence. The evaluators that matter are the ones that catch your specific failure modes, discovered through the error analysis process above.
Running & iterating
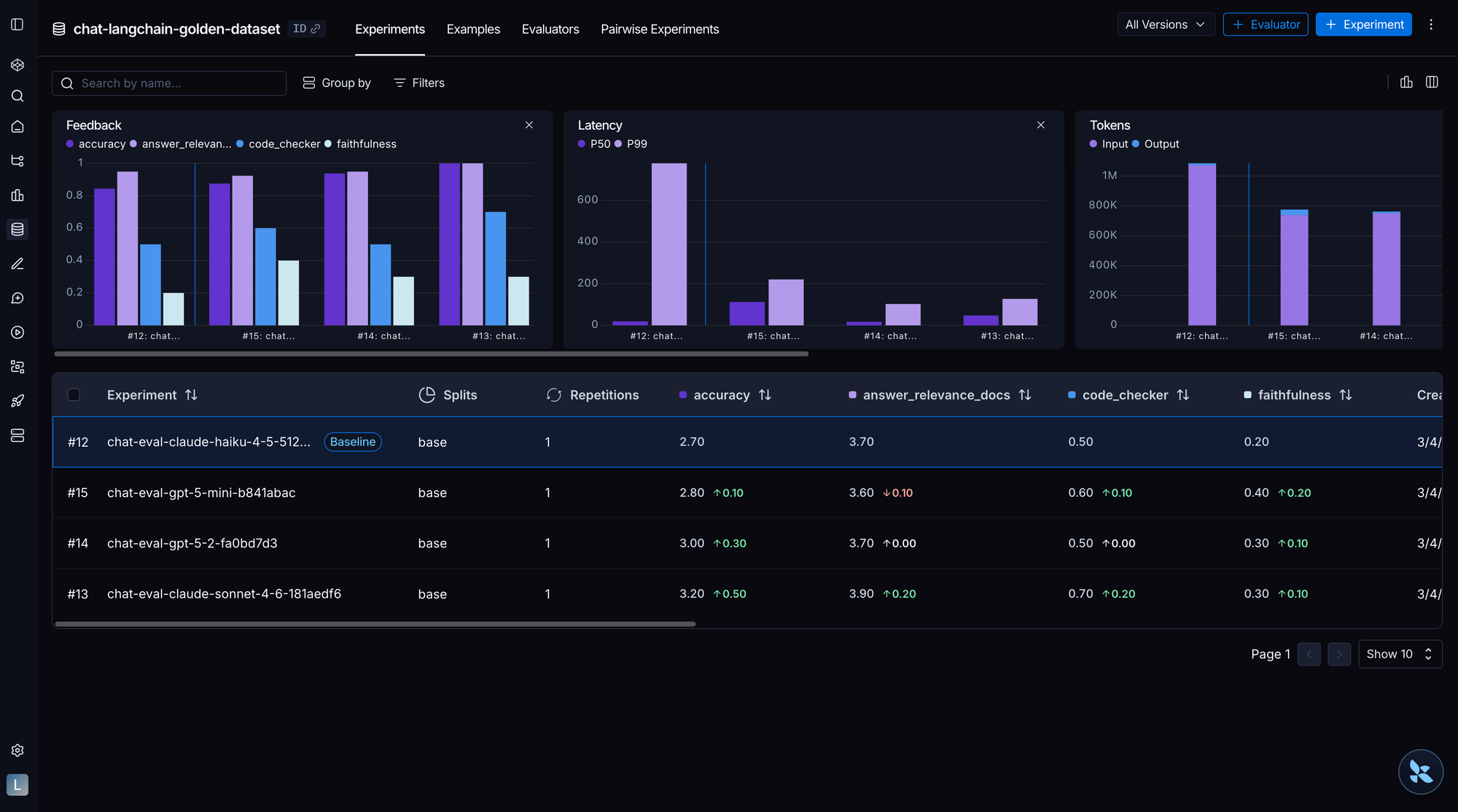
☑️ Distinguish between offline, online, and ad-hoc evaluation and use all three
☑️ Run multiple trials per task to account for non-determinism
☑️ Manually review traces for failed evaluations to verify grader fairness
☑️ Ensure each trial runs in a clean, isolated environment with no shared state
☑️ Tag evals by capability category, document what each measures, and track efficiency metrics (step count, tool calls, latency) alongside quality
☑️ Recognize when pass rates plateau and evolve your test suite accordingly
☑️ Only keep evals that directly measure a production behavior you care about
☑️ Invest in tool interface design and testing, not just prompt optimization
☑️ Distinguish between task failures (agent got it wrong) and evaluation failures (grader got it wrong)
Deep dive
Distinguish between offline, online, and ad-hoc evaluation and use all three
Most of this checklist focuses on offline evaluation, and that's intentional. Offline evals are where you improve with: curated datasets, controlled experiments, iterating before you ship. You'll also need online and ad-hoc evaluation once your agent hits production.
| Timing | What It Is | When to Use |
|---|---|---|
| Offline | Curated datasets, run pre-deployment | Testing changes before they ship |
| Online | Continuous evaluation on production traces | Catching failures in real traffic |
| Ad-hoc | Exploratory analysis of ingested traces | Discovering patterns you didn't anticipate (see Insights) |
The Production readiness section below covers setting up online evaluations and scheduling ad-hoc trace exploration in detail.
Run multiple trials per task to account for non-determinism
Model outputs vary between runs. Use multiple repetitions if not cost prohibitive. When running multiple trials, compute confidence intervals before declaring improvement—single-run benchmarks are noisy. For non-deterministic agents, consider using pass@k (at least one of k attempts succeeds) or pass^k (all k attempts succeed) metrics depending on your product requirements.
Track operational metrics alongside quality: turns taken, token usage, latency, cost per task. An agent that's 95% accurate but 10x slower might not be an improvement.
Tag evals by capability category, document what each measures, and track efficiency metrics alongside quality
Group evals by what they test, not where they come from. Categories like file_operations, retrieval, tool_use, memory, and conversation give you a "middle view" of performance between a single aggregate score and individual test results. Add a docstring to each eval explaining how it measures an agent capability. This keeps intent clear as the suite grows and lets you run targeted subsets (e.g., only tool_use evals after changing a tool definition).
Attach metadata to every experiment so you can filter, group, and compare runs across dimensions that matter. This makes it easy to answer questions like "did switching from GPT-4.1 to Claude Sonnet improve accuracy?" or "which prompt version regressed on this dataset?" without digging through logs. LangSmith automatically captures git info when available, but explicitly tagging model and prompt metadata pays off quickly as your experiment volume grows.
Once quality is established, compare models on efficiency. An agent that's 95% accurate but 10x slower might not be an improvement. Track ratios like observed steps / ideal steps, observed tool calls / ideal tool calls, and observed latency / ideal latency. This doesn't conflict with "grade the outcome, not the exact path": ideal trajectories measure efficiency, not correctness. You still pass an agent that found a creative route, but you can see if it took longer to get there. See the metrics framework in How we build evals for Deep Agents for a worked example.
Manually review traces for failed evaluations to verify grader fairness
A "failed" task might actually be a creative valid solution your grader didn't anticipate. Reading traces is how you know if your graders are being fair.
Ensure each trial runs in a clean, isolated environment with no shared state
If trial 2 can see artifacts from trial 1, your results aren't independent. What this means in practice:
- Coding agents: Fresh containers or VMs per trial
- API-calling agents: Staging environments or mock services
- Database agents: Snapshot and restore between trials
Recognize when pass rates plateau and evolve your test suite accordingly
When your pass rate plateaus and adding more tasks of the same type stops revealing new failure modes, it's time to evolve: add harder tasks, test new capabilities, or shift to different dimensions. Grinding on a saturated eval set wastes effort.
Only keep evals that directly measure a production behavior you care about
Every eval applies pressure on your system over time. It's tempting to blindly add hundreds of tests, but this creates an illusion of progress. You end up optimizing for an eval suite that doesn't reflect what matters in production. More evals does not equal better agents. Build targeted evals, and periodically prune the ones that no longer give you signal. For a concrete example of this approach, see How we build evals for Deep Agents.
Invest in tool interface design and testing, not just prompt optimization
Tool design eliminates entire classes of agent errors. Anthropic's team noted they spent more time optimizing tools than prompts when building their SWE-bench agent. Test how the model actually uses your tools: try different parameter formats (diffs vs full rewrites, JSON vs. markdown), redesign interfaces to make mistakes harder, and invest in clear documentation with examples. The goal is to make mistakes structurally impossible, not just unlikely. For example, requiring absolute file paths eliminates an entire class of navigation errors.
Distinguish between task failures (agent got it wrong) and evaluation failures (grader got it wrong)
Track run status explicitly (complete, error, timeout). A grader that marks a timeout as "incorrect reasoning" pollutes your signal. Separate task failures from evaluation failures to keep your metrics clean.
Production readiness
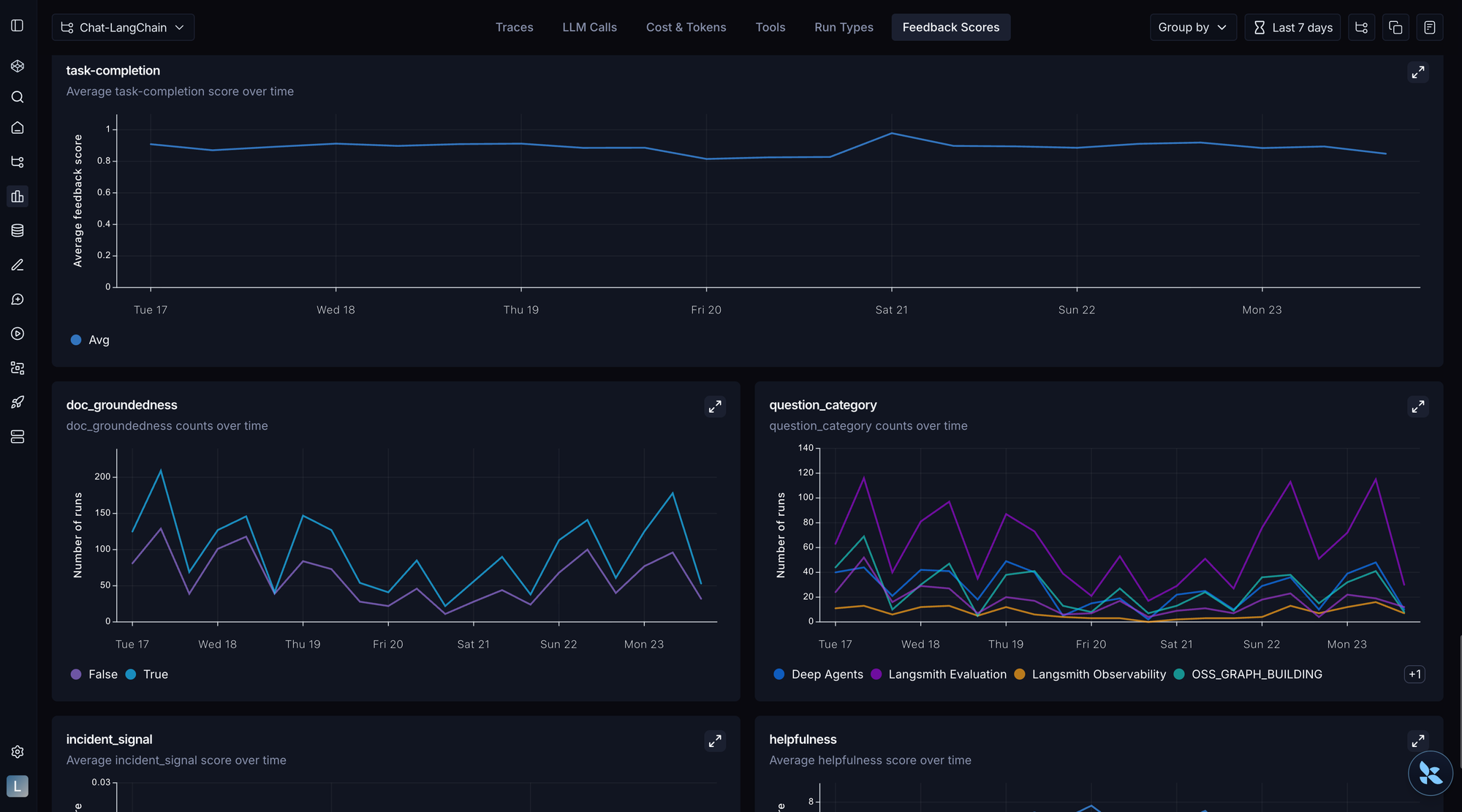
☑️ Promote capability evals with consistently high pass rates into your regression suite
☑️ Integrate regression evals into your CI/CD pipeline with automated quality gates
☑️ Capture user feedback
☑️ Set up online evaluations for production traffic
☑️ Schedule regular manual exploration of production traces beyond automated checks
☑️ Version your prompts and tool definitions alongside your code
☑️ Ensure production failures feed back into datasets, error analysis, and eval improvements
Deep dive
Promote capability evals with consistently high pass rates into your regression suite
Once you've climbed the hill, protect it. Tasks that used to test "can we do this?" become "can we still do this?"
Integrate regression evals into your CI/CD pipeline with automated quality gates
A typical flow:
- Code or prompt change triggers the pipeline (via
git push, PromptHub update, or manual trigger) - Offline evals run unit tests, integration tests, and evaluation against curated datasets using cheap, fast graders
- Preview deployment goes up if offline evals pass
- Online evals run against the preview with live data using LLM-as-judge graders
- Promote to production only if all quality gates pass, otherwise route failing traces to annotation queues and alert the team
Use cheap code-based graders in CI for every commit. Reserve expensive LLM-as-judge evaluations for preview/production evaluation. See LangSmith's CI/CD pipeline guide for a full implementation example with GitHub Actions.
Set up online evaluations for production traffic
Safety checks, format validation, quality heuristics. You'll find failure modes in production you never anticipated (see You don't know what your agent will do until it's in production)
Capture user feedback
Once your agent is in production, user feedback becomes one of your most valuable signals. Automated evals can only catch the failure modes you already know about. Users will surface the ones you don't: edge cases your dataset missed, outputs that are technically correct but unhelpful, and workflows that break in ways you never anticipated.
Capturing this feedback in a structured way lets you feed it back into your datasets, calibrate your graders against real-world expectations, and prioritize the improvements that actually matter to the people using your agent.
Schedule regular manual exploration of production traces beyond automated checks
Don't rely solely on automated pass/fail. Periodically explore production traces for unexpected patterns or failure modes your graders don't cover, surprising user behaviors, or opportunities to improve. Our Insights Agent is a great way to do this!
Version your prompts and tool definitions
LangSmith makes it easy to version your prompts. Without this, you can't correlate eval results with specific changes or know which edit caused a regression.
Ensure production failures feed back into datasets, error analysis, and eval improvements
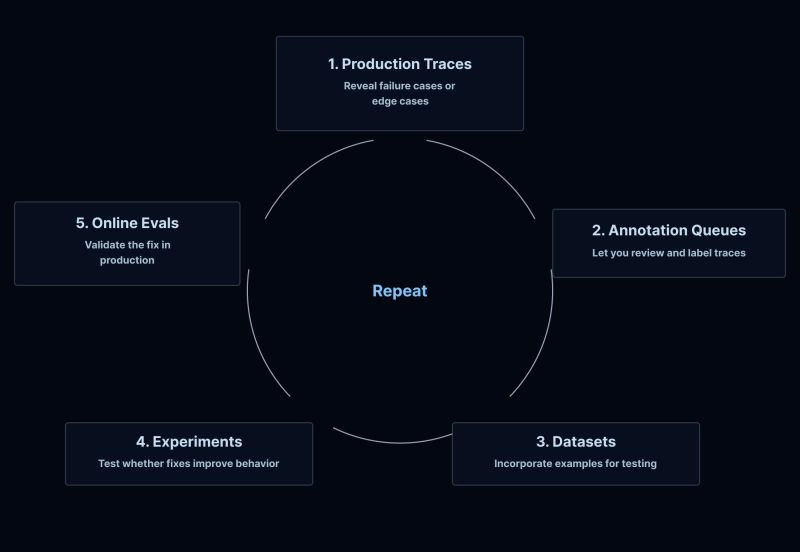
Production successes and failures should feed back into your datasets, error analysis, and eval improvements. This is the flywheel that makes your agent better over time!
You don't need all of these items on day one. Pick the section that matches where you are right now, nail those items, and expand from there. The teams that ship reliable agents aren't the ones with the most sophisticated eval infrastructure - they're the ones who started evaluating early and never stopped iterating.
The full checklist
Before you build evals
⬜️ Manually review 20-50 real agent traces before building any eval infrastructure
⬜️ Define unambiguous success criteria for a single task
⬜️ Separate capability evals from regression evals
⬜️ Ensure you can identify and articulate why each failure occurs
⬜️ Assign eval ownership to a single domain expert
⬜️ Rule out infrastructure and data pipeline issues before blaming the agent
Choose your evaluation level
⬜️ Understand the three evaluation levels: single-step (run), full-turn (trace), and multi-turn (thread)
⬜️ Start with trace-level (full-turn) evals, then layer in run-level and thread-level as needed
Dataset construction
⬜️ Ensure every task is unambiguous, with a reference solution that proves it's solvable
⬜️ Test both positive cases (behavior should occur) and negative cases (behavior should not occur)
⬜️ Ensure dataset structure matches your chosen evaluation level
⬜️ Tailor datasets to your agent type (coding, conversational, research)
⬜️ Generate seed examples if you lack production data
⬜️ Source from dogfooding errors, adapted external benchmarks, and hand-written behavior tests
⬜️ Set up a trace-to-dataset flywheel for continuous improvement
Grader design
⬜️ Select specialized graders per evaluation dimension: default to code-based for objective checks, LLM-as-judge for subjective assessments, human for ambiguous cases, and pairwise for version comparison
⬜️ Distinguish guardrails (inline, runtime) from evaluators (async, quality assessment)
⬜️ Prefer binary pass/fail over numeric scales
⬜️ Calibrate LLM-as-a-Judge graders to human preferences
⬜️ Grade the outcome, not the exact path, and build in partial credit for incremental progress
⬜️ Use custom evaluators derived from your error analysis, not generic off-the-shelf metrics
Running & iterating
⬜️ Distinguish between offline, online, and ad-hoc evaluation and use all three
⬜️ Run multiple trials per task to account for non-determinism
⬜️ Manually review traces for failed evaluations to verify grader fairness
⬜️ Ensure each trial runs in a clean, isolated environment with no shared state
⬜️ Tag evals by capability category, document what each measures, and track efficiency metrics (step count, tool calls, latency) alongside quality
⬜️ Recognize when pass rates plateau and evolve your test suite accordingly
⬜️ Only keep evals that directly measure a production behavior you care about
⬜️ Invest in tool interface design and testing, not just prompt optimization
⬜️ Distinguish between task failures (agent got it wrong) and evaluation failures (grader got it wrong)
Production readiness
⬜️ Promote capability evals with consistently high pass rates into your regression suite
⬜️ Integrate regression evals into your CI/CD pipeline with automated quality gates
⬜️ Capture user feedback
⬜️ Set up online evaluations for production traffic
⬜️ Schedule regular manual exploration of production traces beyond automated checks
⬜️ Version your prompts and tool definitions alongside your code
⬜️ Ensure production failures feed back into datasets, error analysis, and eval improvements
Further reading
LangChain:
- "Agent Observability Powers Agent Evaluation"—the conceptual companion to this checklist
- "You don't know what your agent will do until it's in production"
- "Evaluating skills"
- "How we build evals for Deep Agents"
Witan Labs:
External benchmarks (for sourcing eval tasks):
Anthropic:
OpenAI:
Hamel Husain:
arXiv papers:
LangSmith Docs: